

About Manuel Amunategui
Data scientist with over 20-years experience in the tech industry, MAs in Predictive Analytics and
International Administration, co-author of Monetizing Machine Learning and VP of Data Science at SpringML.
From consulting in machine learning, healthcare modeling, 6 years on Wall Street in the financial industry, and 4 years at Microsoft, I feel like I’ve seen it all. And this has opened my eyes to the huge gap in educational material on applied data science. Like I say:
It just ain’t real 'til it reaches your customer’s plate
I am a startup advisor and available for speaking engagements with companies and schools on topics around building and motivating data science teams, and all things applied machine learning.
Reach me at amunategui@gmail.com


|

Welcome to amunategui.github.io, your portal for practical data science walkthroughs in the Python and R programming languages
I attempt to break down complex machine learning ideas and algorithms into practical applications using clear steps and publicly available data sets. If you're looking for applied walkthroughs of ML and AI concepts, you've come to the right place - happy learning!
Popular/New Posts:



















All Posts:
Grow Your Web Brand, Visibility & Traffic Organically - 5 Years of amunategui.github.io
The Python and Flask Rest API, Abstracting Functions for Web Applications and SaaS
What they Didn’t Teach at Data Science School, and How to Fix It to 10x Your Career
How Blogging and Making YouTube Videos Landed Me the Best Job
My Six Favorite Free Data Science Classes and the Giants Behind Them
Executive Time Management — Don’t Suffocate the Creative Process
Pairing Reinforcement Learning and Machine Learning, an Enhanced Emergency Response Scenario
Find Your Next Programming Language By Measuring “The Knowledge Gap” on StackOverflow.com
Serverless Hosting On Microsoft Azure - A Simple Flask Example
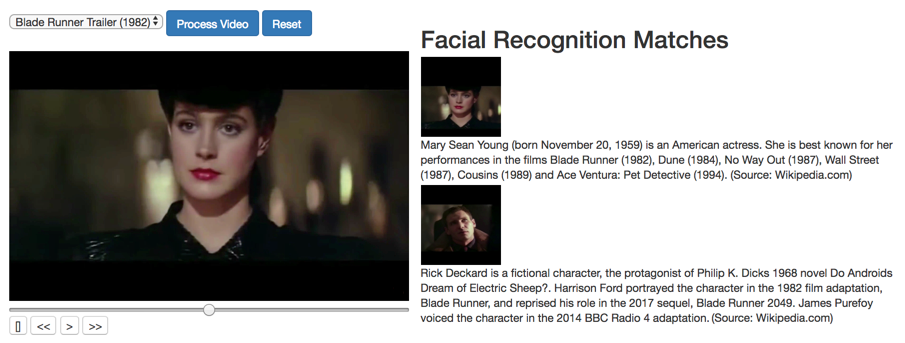
Google Video Intelligence, TensorFlow And Inception V3 - Recognizing Not-So-Famous-People
Rapid Prototyping on Google App Engine - Build a Trip Planner with Google Maps and Yelp
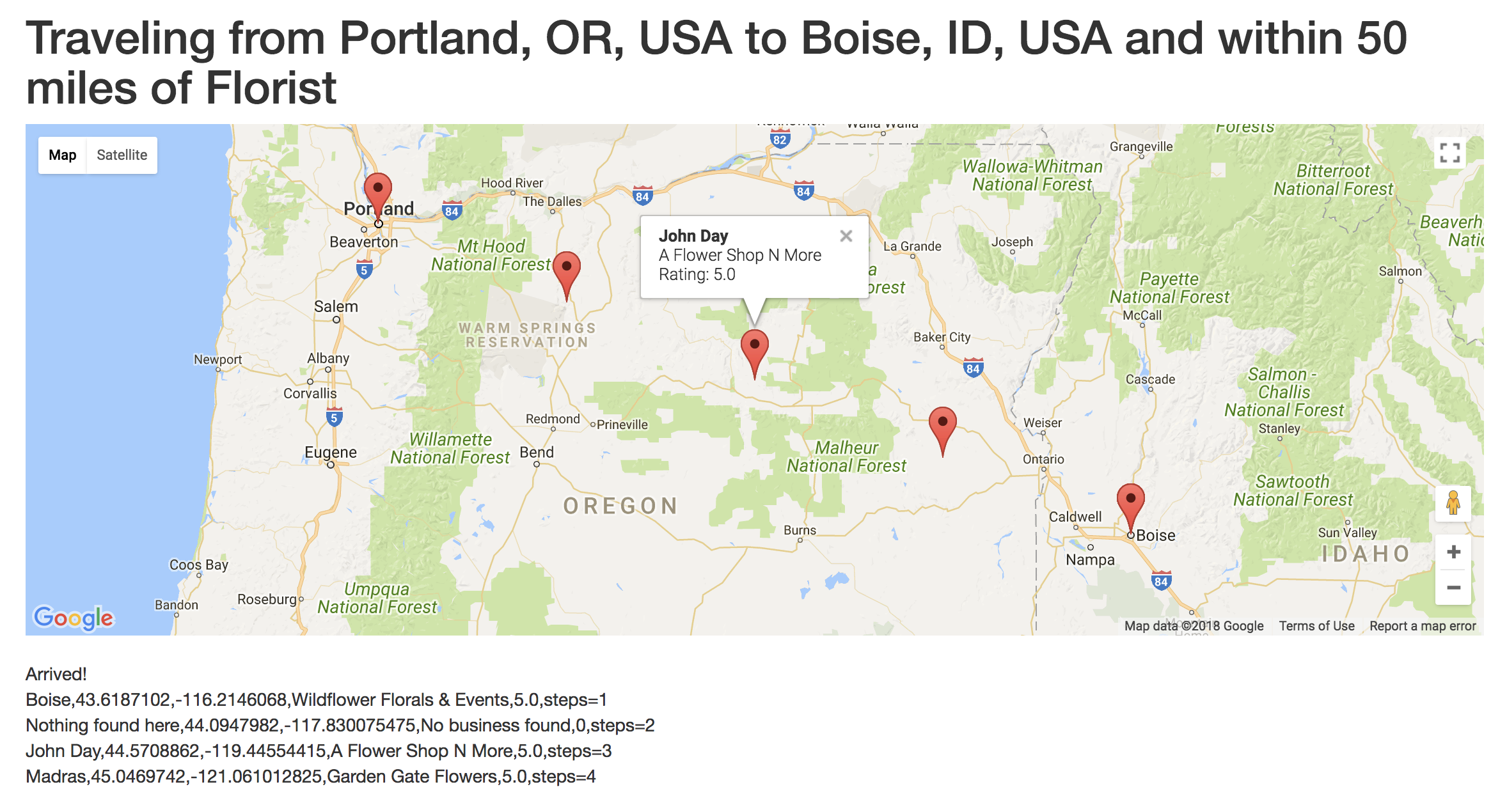
Yelp v3 and a Romantic Trip Across the USA, One Florist at a Time
Show it to the World! Build a Free Art Portfolio Website on GitHub.io in 20 Minutes!
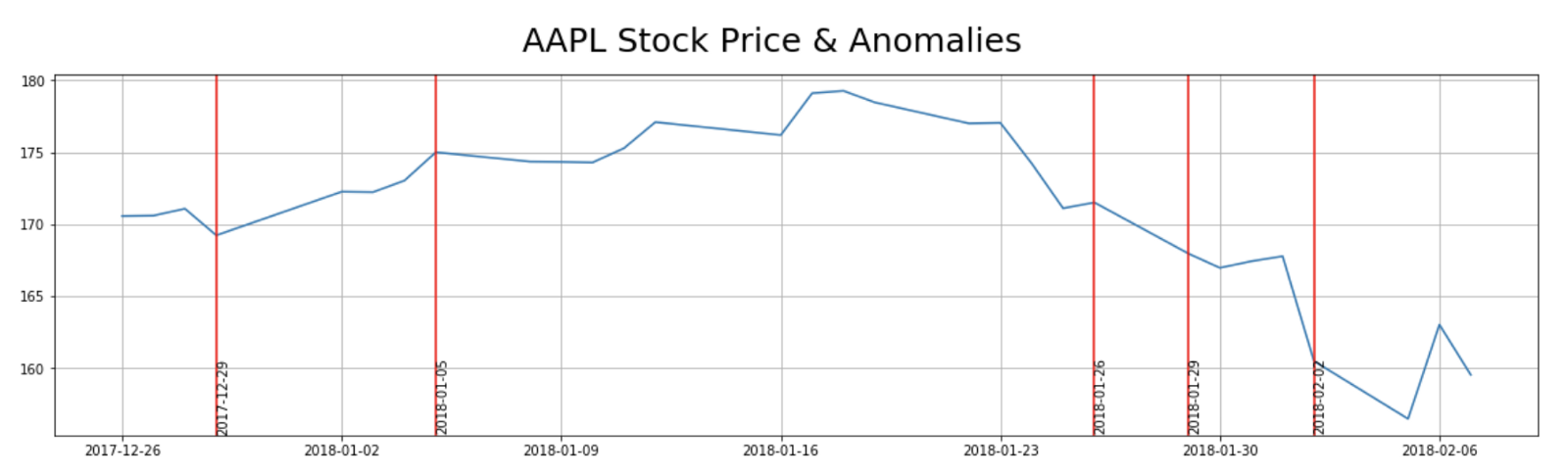
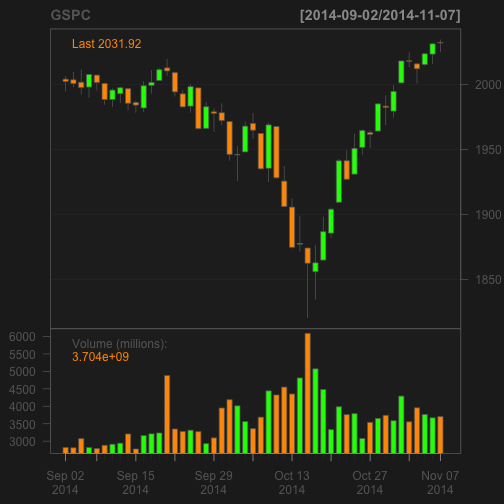
Convolutional Neural Networks And Unconventional Data - Predicting The Stock Market Using Images
Reinforcement Learning - A Simple Python Example and a Step Closer to AI with Assisted Q-Learning
Simple Heuristics - Graphviz and Decision Trees to Quickly Find Patterns in your Data
Office Automation Part 1 - Sorting Departmental Emails with Tensorflow and Word-Embedded Vectors
What-if Roadmap - Assessing Live Opportunities and their Paths to Success or Failure
R and Azure ML - Your One-Stop Modeling Pipeline in The Cloud!
Get Your "all-else-held-equal" Odds-Ratio Story for Non-Linear Models!
Big Data Surveillance: Use EC2, PostgreSQL and Python to Download all Hacker News Data!
Actionable Insights: Getting Variable Importance at the Prediction Level in R
Survival Ensembles: Survival Plus Classification for Improved Time-Based Predictions in R
Anomaly Detection: Increasing Classification Accuracy with H2O's Autoencoder and R
H2O & RStudio Server on Amazon Web Services (AWS), the Easy Way!
Analyze Classic Works of Literature from Around the World with Project Gutenberg and R
Speak Like a Doctor - Use Natural Language Processing to Predict Medical Words in R
Supercharge R with Spark: Getting Apache's SparkR Up and Running on Amazon Web Services (AWS)
Find Variable Importance for any Model - Prediction Shuffling with R
Yelp, httr and a Romantic Trip Across the United States, One Florist at a Time
Quantifying the Spread: Measuring Strength and Direction of Predictors with the Summary Function
Using String Distance {stringdist} To Handle Large Text Factors, Cluster Them Into Supersets
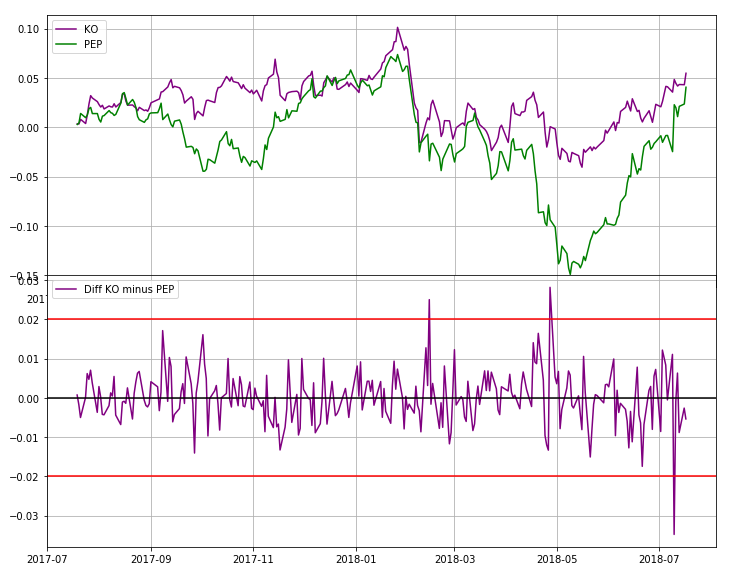
Let's Get Rich! See how {quantmod} And R Can Enrich Your Knowledge Of The Financial Markets!
How To Work With Files Too Large For A Computer’s RAM? Using R To Process Large Data In Chunks
Predicting Multiple Discrete Values with Multinomials, Neural Networks and the {nnet} Package
Modeling 101 - Predicting Binary Outcomes with R, gbm, glmnet, and {caret}
Reducing High Dimensional Data with Principle Component Analysis (PCA) and prcomp
Brief Guide On Running RStudio Server On Amazon Web Services