

About Manuel Amunategui
Data scientist with over 20-years experience in the tech industry, MAs in Predictive Analytics and
International Administration, co-author of Monetizing Machine Learning and VP of Data Science at SpringML.
From consulting in machine learning, healthcare modeling, 6 years on Wall Street in the financial industry, and 4 years at Microsoft, I feel like I’ve seen it all. And this has opened my eyes to the huge gap in educational material on applied data science. Like I say:
It just ain’t real 'til it reaches your customer’s plate
I am a startup advisor and available for speaking engagements with companies and schools on topics around building and motivating data science teams, and all things applied machine learning.
Reach me at amunategui@gmail.com


|

Let's Get Rich! See how {quantmod} And R Can Enrich Your Knowledge Of The Financial Markets!
Practical walkthroughs on machine learning, data exploration and finding insight.
Resources
- YouTube Companion Video
- Full Source Code
- Alternative GBM Source Code <- for those that can't use xgboost!!!
Packages Used in this Walkthrough
- {quantmod} - financial data and modeling tools
- {xts} - handling of time-based data classes
- {xgboost} - fast modeling algorithm
- {pROC} - Area Under the Curve (AUC) functions
This walkthrough has two parts:
- The first part is a very basic introduction to quantmod and, if you haven't used it before and need basic access to daily stock market data and charting, then you're in for a huge treat.
- The second part goes deeper into quantitative finance by leveraging quantmod to access all the stocks composing the NASDAQ 100 Index to build a vocabulary of market moves and attempt to predict whether the following trading day's volumne will be higher or lower.
quantmod stands for “Quantitative Financial Modeling and Trading Framework for R”
It has many features so check out the help file for a full coverage or the Quantmod’s official website.
Let’s see how Amazon has been doing lately:
library(quantmod)
getSymbols(c("AMZN"))
barChart(AMZN,theme='white.mono',bar.type='hlc')
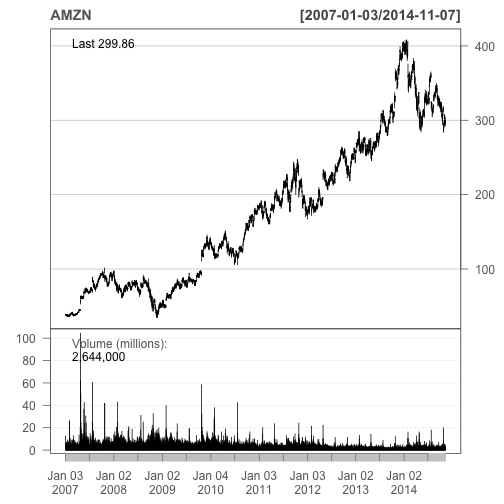
The getSymbols function downloaded daily data going all the way back to January 2007. The barChart function displays the data in a nice clean fashion following a theme-based parameter (see the help file for more). Not bad for 2 lines of code!!
It gets better - let’s see how easy it is to display a full stock chart with indicators in just 3 lines of code:
getSymbols(c("^GSPC"))
chartSeries(GSPC, subset='last 3 months')
addBBands(n = 20, sd = 2, ma = "SMA", draw = 'bands', on = -1)
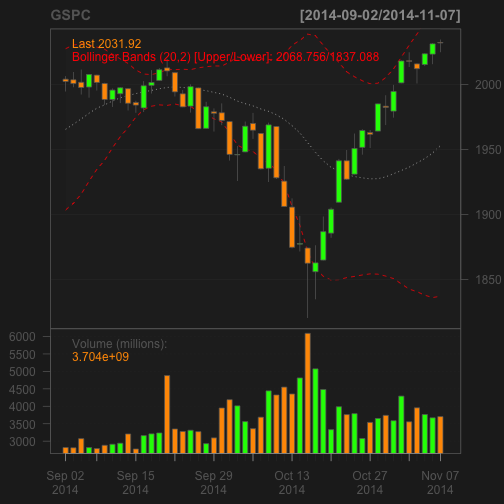
quantmod uses Yahoo to get it’s financial data. In the above example ^GSPC represents the S&P 500 Index. Most financial product symbols are straightforward like MSFT for Microsoft. For indexes and other esoteric symbols, refer to finance.yahoo.com/lookup to see how they abbreviated it.
chartSeries is straightforward and will plot whatever symbol has been downloaded to memory using getSymbols. addBBands function will plot Bollinger Bands around your price series. There are many ways to customize the display, for some examples check out the Quantmod Gallery.
Quant Time
Moving deeper into quantitative finance, let’s design a pattern-based system to predict whether a particular financial product will see a raise or drop in volume the following trading day.
We’ll use quantmod to download all the stocks that compose the NASDAQ 100 Index. Then we’ll merge together all our time series to synchronize them. This will collate the data by time and fill in any missing data with NAs:
Nasdaq100_Symbols <- c("AAPL", "ADBE", "ADI", "ADP", "ADSK", "AKAM", "ALTR", "ALXN",
"AMAT", "AMGN", "AMZN", "ATVI", "AVGO", "BBBY", "BIDU", "BIIB",
"BRCM", "CA", "CELG", "CERN", "CHKP", "CHRW", "CHTR", "CMCSA",
"COST", "CSCO", "CTRX", "CTSH", "CTXS", "DISCA", "DISCK", "DISH",
"DLTR", "DTV", "EBAY", "EQIX", "ESRX", "EXPD", "EXPE", "FAST",
"FB", "FFIV", "FISV", "FOXA", "GILD", "GMCR", "GOOG", "GOOGL",
"GRMN", "HSIC", "ILMN", "INTC", "INTU", "ISRG", "KLAC", "KRFT",
"LBTYA", "LLTC", "LMCA", "LMCK", "LVNTA", "MAR", "MAT", "MDLZ",
"MNST", "MSFT", "MU", "MXIM", "MYL", "NFLX", "NTAP", "NVDA",
"NXPI", "ORLY", "PAYX", "PCAR", "PCLN", "QCOM", "QVCA", "REGN",
"ROST", "SBAC", "SBUX", "SIAL", "SIRI", "SNDK", "SPLS", "SRCL",
"STX", "SYMC", "TRIP", "TSCO", "TSLA", "TXN", "VIAB", "VIP",
"VOD", "VRSK", "VRTX", "WDC", "WFM", "WYNN", "XLNX", "YHOO")
getSymbols(Nasdaq100_Symbols)
## pausing 1 second between requests for more than 5 symbols
...
## [1] "AAPL" "ADBE" "ADI" "ADP" "ADSK" "AKAM" "ALTR" "ALXN"
## [9] "AMAT" "AMGN" "AMZN" "ATVI" "AVGO" "BBBY" "BIDU" "BIIB"
## [17] "BRCM" "CA" "CELG" "CERN" "CHKP" "CHRW" "CHTR" "CMCSA"
## [25] "COST" "CSCO" "CTRX" "CTSH" "CTXS" "DISCA" "DISCK" "DISH"
## [33] "DLTR" "DTV" "EBAY" "EQIX" "ESRX" "EXPD" "EXPE" "FAST"
## [41] "FB" "FFIV" "FISV" "FOXA" "GILD" "GMCR" "GOOG" "GOOGL"
## [49] "GRMN" "HSIC" "ILMN" "INTC" "INTU" "ISRG" "KLAC" "KRFT"
## [57] "LBTYA" "LLTC" "LMCA" "LMCK" "LVNTA" "MAR" "MAT" "MDLZ"
## [65] "MNST" "MSFT" "MU" "MXIM" "MYL" "NFLX" "NTAP" "NVDA"
## [73] "NXPI" "ORLY" "PAYX" "PCAR" "PCLN" "QCOM" "QVCA" "REGN"
## [81] "ROST" "SBAC" "SBUX" "SIAL" "SIRI" "SNDK" "SPLS" "SRCL"
## [89] "STX" "SYMC" "TRIP" "TSCO" "TSLA" "TXN" "VIAB" "VIP"
## [97] "VOD" "VRSK" "VRTX" "WDC" "WFM" "WYNN" "XLNX" "YHOO"
Be warned, that this does take a little time as quantmod will throttle the download. Each symbol is loaded in memory under the symbol name, therefore we have over 100 new objects loaded in memory each with years of daily market data. As these are independent time series, we have to merge everything together and fill in missing data so everything fits nicely in a data frame. We’ll use the merge.xts function to merge by time all these objects into one data frame:
nasdaq100 <- data.frame(as.xts(merge(AAPL, ADBE, ADI, ADP, ADSK, AKAM,
ALTR, ALXN,AMAT, AMGN, AMZN, ATVI, AVGO, BBBY, BIDU, BIIB,
BRCM, CA, CELG, CERN, CHKP, CHRW, CHTR, CMCSA,
COST, CSCO, CTRX, CTSH, CTXS, DISCA, DISCK, DISH,
DLTR, DTV, EBAY, EQIX, ESRX, EXPD, EXPE, FAST,
FB, FFIV, FISV, FOXA, GILD, GMCR, GOOG, GOOGL,
GRMN, HSIC, ILMN, INTC, INTU, ISRG, KLAC, KRFT,
LBTYA, LLTC, LMCA, LMCK, LVNTA, MAR, MAT, MDLZ,
MNST, MSFT, MU, MXIM, MYL, NFLX, NTAP, NVDA,
NXPI, ORLY, PAYX, PCAR, PCLN, QCOM, QVCA, REGN,
ROST, SBAC, SBUX, SIAL, SIRI, SNDK, SPLS, SRCL,
STX, SYMC, TRIP, TSCO, TSLA, TXN, VIAB, VIP,
VOD, VRSK, VRTX, WDC, WFM, WYNN, XLNX, YHOO)))
head(nasdaq100[,1:12],2)
## AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume
## 2007-01-03 86.29 86.58 81.90 83.80 309579900
## 2007-01-04 84.05 85.95 83.82 85.66 211815100
## AAPL.Adjusted ADBE.Open ADBE.High ADBE.Low ADBE.Close
## 2007-01-03 11.34 40.72 41.32 38.89 39.92
## 2007-01-04 11.59 39.88 41.00 39.43 40.82
## ADBE.Volume ADBE.Adjusted
## 2007-01-03 7126000 39.92
## 2007-01-04 4503700 40.82
Now that we have a handful of years of market data for every stock currently in the NASDAQ 100 Index, we need to do something with it. We’re going to create a variety of measures between price and volume points. The idea is to quantify stock moves as patterns by subtracting one day versus a previous one. We’ll create a series of differences:
- 1 day versus 2 days ago
- 1 day versus 3 days ago
- 1 day versus 5 days ago
- 1 day versus 20 days ago (akin a 20 day moving average)
Hi there, this is Manuel Amunategui- if you're enjoying the content, find more at ViralML.com
Creating The Outcome Variable
This is the heart of the system and it’s a bit tedious so hold on. What are we trying to predict?
Whether the next trading day’s volume for a chosen symbol will be higher or lower than the current trading day (this doesn’t have to be the volume field of FISV, it could be the high or close of any other symbol for which we have data):
outcomeSymbol <- 'FISV.Volume'
Shift the result we’re trying to predict down one trading day using the lag function. This will add the volume field of our outcome symbol with a lag of 1 trading day so it’s on the same line as the predictors. We will rely on this value for training and testing purposes. A value of 1 means the volume went up, and a 0, that it went down:
library(xts)
nasdaq100 <- xts(nasdaq100,order.by=as.Date(rownames(nasdaq100)))
nasdaq100 <- as.data.frame(merge(nasdaq100, lm1=lag(nasdaq100[,outcomeSymbol],-1)))
nasdaq100$outcome <- ifelse(nasdaq100[,paste0(outcomeSymbol,'.1')] > nasdaq100[,outcomeSymbol], 1, 0)
# remove shifted down volume field as we don't care by the value
nasdaq100 <- nasdaq100[,!names(nasdaq100) %in% c(paste0(outcomeSymbol,'.1'))]
Cast the date field to type date as it currently is of type character and sort by decreasing order:
nasdaq100$date <- as.Date(row.names(nasdaq100))
nasdaq100 <- nasdaq100[order(as.Date(nasdaq100$date, "%m/%d/%Y"), decreasing = TRUE),]
Here is the pattern maker function. This will take our raw market data and scale it so that we can compare any symbol with any other symbol. It then subtracts the different day ranges requested by the days parameter using the diff and lag calls and puts them all on the same row along with the outcome. To make things even more compatible, the roundByScaler parameter can round results.
GetDiffDays <- function(objDF,days=c(10), offLimitsSymbols=c('outcome'), roundByScaler=3) {
# needs to be sorted by date in decreasing order
ind <- sapply(objDF, is.numeric)
for (sym in names(objDF)[ind]) {
if (!sym %in% offLimitsSymbols) {
print(paste('*********', sym))
objDF[,sym] <- round(scale(objDF[,sym]),roundByScaler)
print(paste('theColName', sym))
for (day in days) {
objDF[paste0(sym,'_',day)] <- c(diff(objDF[,sym],lag = day),rep(x=0,day)) * -1
}
}
}
return (objDF)
}
Call the function with the following differences and scale it down to 2 decimal points (this takes a little while to run):
nasdaq100 <- GetDiffDays(nasdaq100, days=c(1,2,3,4,5,10,20), offLimitsSymbols=c('outcome'), roundByScaler=2)
## [1] "********* AAPL.Open"
## [1] "theColName AAPL.Open"
## [1] "********* AAPL.High"
## [1] "theColName AAPL.High"
## [1] "********* AAPL.Low"
## [1] "theColName AAPL.Low"
## [1] "********* AAPL.Close"
## [1] "theColName AAPL.Close"
## [1] "********* AAPL.Volume"
## [1] "theColName AAPL.Volume"
## [1] "********* AAPL.Adjusted"
## [1] "theColName AAPL.Adjusted"
...
## [1] "********* YHOO.Open"
## [1] "theColName YHOO.Open"
## [1] "********* YHOO.High"
## [1] "theColName YHOO.High"
## [1] "********* YHOO.Low"
## [1] "theColName YHOO.Low"
## [1] "********* YHOO.Close"
## [1] "theColName YHOO.Close"
## [1] "********* YHOO.Volume"
## [1] "theColName YHOO.Volume"
## [1] "********* YHOO.Adjusted"
## [1] "theColName YHOO.Adjusted"
We delete the last row from our data frame as it doesn’t have an outcome variable (that is in the future):
nasdaq100 <- nasdaq100[2:nrow(nasdaq100),]
Let’s take a peek at our resulting features for Yahoo:
dput(names(nasdaq100)[grepl('YHOO.',names(nasdaq100))])
## c("YHOO.Open", "YHOO.High", "YHOO.Low", "YHOO.Close", "YHOO.Volume",
## "YHOO.Adjusted", "YHOO.Open_1", "YHOO.Open_2", "YHOO.Open_3",
## "YHOO.Open_4", "YHOO.Open_5", "YHOO.Open_10", "YHOO.Open_20",
## "YHOO.High_1", "YHOO.High_2", "YHOO.High_3", "YHOO.High_4", "YHOO.High_5",
## "YHOO.High_10", "YHOO.High_20", "YHOO.Low_1", "YHOO.Low_2", "YHOO.Low_3",
## "YHOO.Low_4", "YHOO.Low_5", "YHOO.Low_10", "YHOO.Low_20", "YHOO.Close_1",
## "YHOO.Close_2", "YHOO.Close_3", "YHOO.Close_4", "YHOO.Close_5",
## "YHOO.Close_10", "YHOO.Close_20", "YHOO.Volume_1", "YHOO.Volume_2",
## "YHOO.Volume_3", "YHOO.Volume_4", "YHOO.Volume_5", "YHOO.Volume_10",
## "YHOO.Volume_20", "YHOO.Adjusted_1", "YHOO.Adjusted_2", "YHOO.Adjusted_3",
## "YHOO.Adjusted_4", "YHOO.Adjusted_5", "YHOO.Adjusted_10", "YHOO.Adjusted_20"
## )
We extract the day of the week, day of the month, day of the year as predictors using POSIXlt:
nasdaq100$wday <- as.POSIXlt(nasdaq100$date)$wday
nasdaq100$yday <- as.POSIXlt(nasdaq100$date)$mday
nasdaq100$mon <- as.POSIXlt(nasdaq100$date)$mon
Next we remove the date field as it won’t help us as a predictor as they are all unique and we shuffle the data set using the sample function:
nasdaq100 <- subset(nasdaq100, select=-c(date))
nasdaq100 <- nasdaq100[sample(nrow(nasdaq100)),]
Let’s Model It!
We’ll use a simple xgboost model to get an AUC score. You can get more details regarding parameter settings for this model at the xgboost wiki:
library(xgboost)
predictorNames <- names(nasdaq100)[names(nasdaq100) != 'outcome']
set.seed(1234)
split <- sample(nrow(nasdaq100), floor(0.7*nrow(nasdaq100)))
train <-nasdaq100[split,]
test <- nasdaq100[-split,]
bst <- xgboost(data = as.matrix(train[,predictorNames]),
label = train$outcome,
verbose=0,
eta = 0.1,
gamma = 50,
nround = 50,
missing = NaN,
colsample_bytree = 0.1,
subsample = 8.6,
objective="binary:logistic")
predictions <- predict(bst, as.matrix(test[,predictorNames]), missing = NaN, outputmargin=TRUE)
library(pROC)
auc <- roc(test$outcome, predictions)
print(paste('AUC score:', auc$auc))
## [1] "AUC score: 0.719931972789116"
Conclusion
Not bad, right? An AUC of 0.719 for very little work (remember that an AUC ranges between 0.5 and 1, where 0.5 is random and 1 is perfect). Hopefully this will pique your imagination with the many possibilities of quantmod and R.
Full source code (also on GitHub):
library(quantmod)
# display a simple bar chart
getSymbols(c("AMZN"))
barChart(AMZN,theme='white.mono',bar.type='hlc')
# display a complex chart
getSymbols(c("^GSPC"))
chartSeries(GSPC, subset='last 3 months')
addBBands(n = 20, sd = 2, ma = "SMA", draw = 'bands', on = -1)
# get market data for all symbols making up the NASDAQ 100 Index
Nasdaq100_Symbols <- c("AAPL", "ADBE", "ADI", "ADP", "ADSK", "AKAM", "ALTR", "ALXN",
"AMAT", "AMGN", "AMZN", "ATVI", "AVGO", "BBBY", "BIDU", "BIIB",
"BRCM", "CA", "CELG", "CERN", "CHKP", "CHRW", "CHTR", "CMCSA",
"COST", "CSCO", "CTRX", "CTSH", "CTXS", "DISCA", "DISCK", "DISH",
"DLTR", "DTV", "EBAY", "EQIX", "ESRX", "EXPD", "EXPE", "FAST",
"FB", "FFIV", "FISV", "FOXA", "GILD", "GMCR", "GOOG", "GOOGL",
"GRMN", "HSIC", "ILMN", "INTC", "INTU", "ISRG", "KLAC", "KRFT",
"LBTYA", "LLTC", "LMCA", "LMCK", "LVNTA", "MAR", "MAT", "MDLZ",
"MNST", "MSFT", "MU", "MXIM", "MYL", "NFLX", "NTAP", "NVDA",
"NXPI", "ORLY", "PAYX", "PCAR", "PCLN", "QCOM", "QVCA", "REGN",
"ROST", "SBAC", "SBUX", "SIAL", "SIRI", "SNDK", "SPLS", "SRCL",
"STX", "SYMC", "TRIP", "TSCO", "TSLA", "TXN", "VIAB", "VIP",
"VOD", "VRSK", "VRTX", "WDC", "WFM", "WYNN", "XLNX", "YHOO")
getSymbols(Nasdaq100_Symbols)
# merge them all together
nasdaq100 <- data.frame(as.xts(merge(AAPL, ADBE, ADI, ADP, ADSK, AKAM,
ALTR, ALXN,AMAT, AMGN, AMZN, ATVI, AVGO, BBBY, BIDU, BIIB,
BRCM, CA, CELG, CERN, CHKP, CHRW, CHTR, CMCSA,
COST, CSCO, CTRX, CTSH, CTXS, DISCA, DISCK, DISH,
DLTR, DTV, EBAY, EQIX, ESRX, EXPD, EXPE, FAST,
FB, FFIV, FISV, FOXA, GILD, GMCR, GOOG, GOOGL,
GRMN, HSIC, ILMN, INTC, INTU, ISRG, KLAC, KRFT,
LBTYA, LLTC, LMCA, LMCK, LVNTA, MAR, MAT, MDLZ,
MNST, MSFT, MU, MXIM, MYL, NFLX, NTAP, NVDA,
NXPI, ORLY, PAYX, PCAR, PCLN, QCOM, QVCA, REGN,
ROST, SBAC, SBUX, SIAL, SIRI, SNDK, SPLS, SRCL,
STX, SYMC, TRIP, TSCO, TSLA, TXN, VIAB, VIP,
VOD, VRSK, VRTX, WDC, WFM, WYNN, XLNX, YHOO)))
head(nasdaq100[,1:12],2)
# set outcome variable
outcomeSymbol <- 'FISV.Volume'
# shift outcome value to be on same line as predictors
library(xts)
nasdaq100 <- xts(nasdaq100,order.by=as.Date(rownames(nasdaq100)))
nasdaq100 <- as.data.frame(merge(nasdaq100, lm1=lag(nasdaq100[,outcomeSymbol],-1)))
nasdaq100$outcome <- ifelse(nasdaq100[,paste0(outcomeSymbol,'.1')] > nasdaq100[,outcomeSymbol], 1, 0)
# remove shifted down volume field as we don't care by the value
nasdaq100 <- nasdaq100[,!names(nasdaq100) %in% c(paste0(outcomeSymbol,'.1'))]
# cast date to true date and order in decreasing order
nasdaq100$date <- as.Date(row.names(nasdaq100))
nasdaq100 <- nasdaq100[order(as.Date(nasdaq100$date, "%m/%d/%Y"), decreasing = TRUE),]
# calculate all day differences and populate them on same row
GetDiffDays <- function(objDF,days=c(10), offLimitsSymbols=c('outcome'), roundByScaler=3) {
# needs to be sorted by date in decreasing order
ind <- sapply(objDF, is.numeric)
for (sym in names(objDF)[ind]) {
if (!sym %in% offLimitsSymbols) {
print(paste('*********', sym))
objDF[,sym] <- round(scale(objDF[,sym]),roundByScaler)
print(paste('theColName', sym))
for (day in days) {
objDF[paste0(sym,'_',day)] <- c(diff(objDF[,sym],lag = day),rep(x=0,day)) * -1
}
}
}
return (objDF)
}
# call the function with the following differences
nasdaq100 <- GetDiffDays(nasdaq100, days=c(1,2,3,4,5,10,20), offLimitsSymbols=c('outcome'), roundByScaler=2)
# drop most recent entry as we don't have an outcome
nasdaq100 <- nasdaq100[2:nrow(nasdaq100),]
# take a peek at YHOO features:
dput(names(nasdaq100)[grepl('YHOO.',names(nasdaq100))])
# well use POSIXlt to add day of the week, day of the month, day of the year
nasdaq100$wday <- as.POSIXlt(nasdaq100$date)$wday
nasdaq100$yday <- as.POSIXlt(nasdaq100$date)$mday
nasdaq100$mon<- as.POSIXlt(nasdaq100$date)$mon
# remove date field and shuffle data frame
nasdaq100 <- subset(nasdaq100, select=-c(date))
nasdaq100 <- nasdaq100[sample(nrow(nasdaq100)),]
# let's model
library(xgboost)
predictorNames <- names(nasdaq100)[names(nasdaq100) != 'outcome']
set.seed(1234)
split <- sample(nrow(nasdaq100), floor(0.7*nrow(nasdaq100)))
train <-nasdaq100[split,]
test <- nasdaq100[-split,]
bst <- xgboost(data = as.matrix(train[,predictorNames]),
label = train$outcome,
verbose=0,
eta = 0.1,
gamma = 50,
missing = NaN,
nround = 50,
colsample_bytree = 0.1,
subsample = 8.6,
objective="binary:logistic")
predictions <- predict(bst, as.matrix(test[,predictorNames]), missing = NaN, outputmargin=TRUE)
library(pROC)
auc <- roc(test$outcome, predictions)
print(paste('AUC score:', auc$auc))
library(quantmod)
# display a simple bar chart
getSymbols(c("AMZN"))
barChart(AMZN,theme='white.mono',bar.type='hlc')
# display a complex chart
getSymbols(c("^GSPC"))
chartSeries(GSPC, subset='last 3 months')
addBBands(n = 20, sd = 2, ma = "SMA", draw = 'bands', on = -1)
# get market data for all symbols making up the NASDAQ 100 Index
Nasdaq100_Symbols <- c("AAPL", "ADBE", "ADI", "ADP", "ADSK", "AKAM", "ALTR", "ALXN",
"AMAT", "AMGN", "AMZN", "ATVI", "AVGO", "BBBY", "BIDU", "BIIB",
"BRCM", "CA", "CELG", "CERN", "CHKP", "CHRW", "CHTR", "CMCSA",
"COST", "CSCO", "CTRX", "CTSH", "CTXS", "DISCA", "DISCK", "DISH",
"DLTR", "DTV", "EBAY", "EQIX", "ESRX", "EXPD", "EXPE", "FAST",
"FB", "FFIV", "FISV", "FOXA", "GILD", "GMCR", "GOOG", "GOOGL",
"GRMN", "HSIC", "ILMN", "INTC", "INTU", "ISRG", "KLAC", "KRFT",
"LBTYA", "LLTC", "LMCA", "LMCK", "LVNTA", "MAR", "MAT", "MDLZ",
"MNST", "MSFT", "MU", "MXIM", "MYL", "NFLX", "NTAP", "NVDA",
"NXPI", "ORLY", "PAYX", "PCAR", "PCLN", "QCOM", "QVCA", "REGN",
"ROST", "SBAC", "SBUX", "SIAL", "SIRI", "SNDK", "SPLS", "SRCL",
"STX", "SYMC", "TRIP", "TSCO", "TSLA", "TXN", "VIAB", "VIP",
"VOD", "VRSK", "VRTX", "WDC", "WFM", "WYNN", "XLNX", "YHOO")
getSymbols(Nasdaq100_Symbols)
# merge them all together
nasdaq100 <- data.frame(as.xts(merge(AAPL, ADBE, ADI, ADP, ADSK, AKAM,
ALTR, ALXN,AMAT, AMGN, AMZN, ATVI, AVGO, BBBY, BIDU, BIIB,
BRCM, CA, CELG, CERN, CHKP, CHRW, CHTR, CMCSA,
COST, CSCO, CTRX, CTSH, CTXS, DISCA, DISCK, DISH,
DLTR, DTV, EBAY, EQIX, ESRX, EXPD, EXPE, FAST,
FB, FFIV, FISV, FOXA, GILD, GMCR, GOOG, GOOGL,
GRMN, HSIC, ILMN, INTC, INTU, ISRG, KLAC, KRFT,
LBTYA, LLTC, LMCA, LMCK, LVNTA, MAR, MAT, MDLZ,
MNST, MSFT, MU, MXIM, MYL, NFLX, NTAP, NVDA,
NXPI, ORLY, PAYX, PCAR, PCLN, QCOM, QVCA, REGN,
ROST, SBAC, SBUX, SIAL, SIRI, SNDK, SPLS, SRCL,
STX, SYMC, TRIP, TSCO, TSLA, TXN, VIAB, VIP,
VOD, VRSK, VRTX, WDC, WFM, WYNN, XLNX, YHOO)))
head(nasdaq100[,1:12],2)
# set outcome variable
outcomeSymbol <- 'FISV.Volume'
# shift outcome value to be on same line as predictors
library(xts)
nasdaq100 <- xts(nasdaq100,order.by=as.Date(rownames(nasdaq100)))
nasdaq100 <- as.data.frame(merge(nasdaq100, lm1=lag(nasdaq100[,outcomeSymbol],-1)))
nasdaq100$outcome <- ifelse(nasdaq100[,paste0(outcomeSymbol,'.1')] > nasdaq100[,outcomeSymbol], 1, 0)
# remove shifted down volume field as we don't care by the value
nasdaq100 <- nasdaq100[,!names(nasdaq100) %in% c(paste0(outcomeSymbol,'.1'))]
# cast date to true date and order in decreasing order
nasdaq100$date <- as.Date(row.names(nasdaq100))
nasdaq100 <- nasdaq100[order(as.Date(nasdaq100$date, "%m/%d/%Y"), decreasing = TRUE),]
# calculate all day differences and populate them on same row
GetDiffDays <- function(objDF,days=c(10), offLimitsSymbols=c('outcome'), roundByScaler=3) {
# needs to be sorted by date in decreasing order
ind <- sapply(objDF, is.numeric)
for (sym in names(objDF)[ind]) {
if (!sym %in% offLimitsSymbols) {
print(paste('*********', sym))
objDF[,sym] <- round(scale(objDF[,sym]),roundByScaler)
print(paste('theColName', sym))
for (day in days) {
objDF[paste0(sym,'_',day)] <- c(diff(objDF[,sym],lag = day),rep(x=0,day)) * -1
}
}
}
return (objDF)
}
# call the function with the following differences
nasdaq100 <- GetDiffDays(nasdaq100, days=c(1,2,3,4,5,10,20), offLimitsSymbols=c('outcome'), roundByScaler=2)
# drop most recent entry as we don't have an outcome
nasdaq100 <- nasdaq100[2:nrow(nasdaq100),]
# take a peek at YHOO features:
dput(names(nasdaq100)[grepl('YHOO.',names(nasdaq100))])
# well use POSIXlt to add day of the week, day of the month, day of the year
nasdaq100$wday <- as.POSIXlt(nasdaq100$date)$wday
nasdaq100$yday <- as.POSIXlt(nasdaq100$date)$mday
nasdaq100$mon<- as.POSIXlt(nasdaq100$date)$mon
# remove date field and shuffle data frame
nasdaq100 <- subset(nasdaq100, select=-c(date))
nasdaq100 <- nasdaq100[sample(nrow(nasdaq100)),]
# let's model
library(caret)
predictorNames <- names(nasdaq100)[names(nasdaq100) != 'outcome']
set.seed(1234)
split <- sample(nrow(nasdaq100), floor(0.7*nrow(nasdaq100)))
train <-nasdaq100[split,]
test <- nasdaq100[-split,]
train$outcome <- ifelse(train$outcome==1,'yes','nope')
# create caret trainControl object to control the number of cross-validations performed
objControl <- trainControl(method='cv', number=2, returnResamp='none', summaryFunction = twoClassSummary, classProbs = TRUE)
# run model
bst <- train(train[,predictorNames], as.factor(train$outcome),
method='gbm',
trControl=objControl,
metric = "ROC",
tuneGrid = expand.grid(n.trees = 5, interaction.depth = 3, shrinkage = 0.1)
)
predictions <- predict(object=bst, train[,predictorNames], type='prob')
library(pROC)
auc <- auc(train$outcome,predictions[[2]])
print(paste('AUC score:', auc))
Manuel Amunategui - Follow me on Twitter: @amunategui