

About Manuel Amunategui
Data scientist with over 20-years experience in the tech industry, MAs in Predictive Analytics and
International Administration, co-author of Monetizing Machine Learning and VP of Data Science at SpringML.
From consulting in machine learning, healthcare modeling, 6 years on Wall Street in the financial industry, and 4 years at Microsoft, I feel like I’ve seen it all. And this has opened my eyes to the huge gap in educational material on applied data science. Like I say:
It just ain’t real 'til it reaches your customer’s plate
I am a startup advisor and available for speaking engagements with companies and schools on topics around building and motivating data science teams, and all things applied machine learning.
Reach me at amunategui@gmail.com


|

Pairing Reinforcement Learning and Machine Learning, an Enhanced Emergency Response Scenario
Practical walkthroughs on machine learning, data exploration and finding insight.
On YouTube:
|
Companion Code on GitHub:

|

Art credit: Lucas Amunategui
Imagine a scenario unraveling at a chemical factory right after an explosion that caused a dangerous chemical leak. The alarms are blazing and the personnel is evacuated as the leak cannot be located. They send an autonomous robot inside the empty factory equipped with a camera, lights, and environmental sensors, capable of capturing ambient humidity, in hopes of locating the chemical leak.
The robot has the ability to travel quickly and at ease through each room of the factory without any prior knowledge of the layout. Its primary goal is to find the shortest path to the leak by exploring each room and using its humidity sensor and camera. The robot’s decision-making framework uses reinforcement learning and will start traveling at random throughout the factory floor many times, recording each path taken in detail to eventually determine the shortest route to the leak. The goal isn’t only to find the leak but also to find the shortest path. This will be of tremendous help to the emergency crew to quickly locate the danger and limit human exposure to chemicals.
As Q-Learning requires constant back-and-forth and trial-and-error towards finding a shortest path, why not make use of that discovery process to record as much environmental data as possible? With the rise in popularity of Internet of Things (IoT), there are plenty of third-party sensor attachments, hardware and software management tools to leverage. This could be as simple as attaching a temperature-sensing gauge on the bot with built-in data storage or realtime transmission capabilities. The hope is to analyze the data after each incident and learn more than simply the shortest path.
We then extend this scenario to another factory facing a similar chemical-leak situation. This time the software in the bot is enhanced with an additional system to leverage the IoT lessons learned from the first experience. The bot won’t only look for the shortest path to the leak but will also use environmental lessons it learned from the first incident.
Let’s see how the process of search and discovery can be enhanced when combining Reinforcement Learning (RL), Machine Learning (ML), Internet of Things (IoT), and Case-based reasoning (CBR).
Note: For a gentle introduction to RL and Q-Learning in Python, see a post I made on my Github blog http://amunategui.github.io/reinforcement-learning/index.html
Finding the Factory Floor with the Dangerous Chemical Leak
The goal in this experiment is to apply Q-Learning method to map the shortest path to a chemical leak for response team. The factory floor plan considered for this experiment comprises 57 rooms in which the entrance and the goal are considered at room 0 and 50 respectively (see Figure 1).
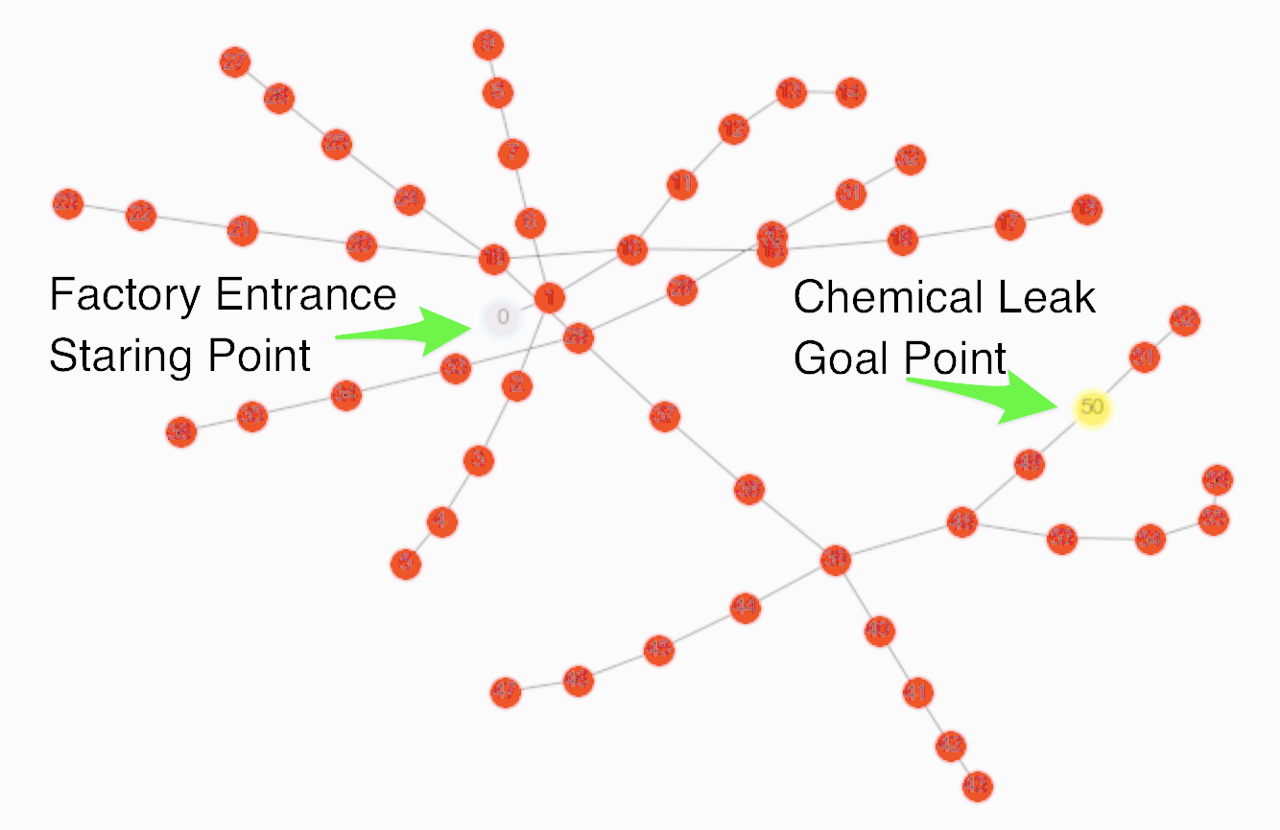
Figure 1: Shows the graph representation of our chemical
factory. Each colored circle is a room. The entrance to the factory is room ‘0’
and the room with the chemical leak is room ‘50’.
Q-Learning is an unsupervised learning process that will iterate thousands of times to map and learn the fastest route to a goal point –room ‘50’ in our case. The bot learns using an intelligent rewards-feedback mechanism. This is done with the help of a rewards table, a large matrix used to score each path the bot can follow. This is the matrix version of a road map. We initialize the matrix to be the height and width of all our points (64 in this example) and initialize all values to –1. We then change the viable paths to value 0 and goal paths to 100 (you can make the goal score anything you want as long as its larger enough to propagate during Q-Learning).
When the model starts, it creates a blank Q-matrix (hence the name Q-Learning), which is a matrix the same size as the rewards matrix but all values are initialized to 0. It is this Q-matrix that our model will use to keep track and score how well the paths are doing. Each attempt is scored using the following formula:
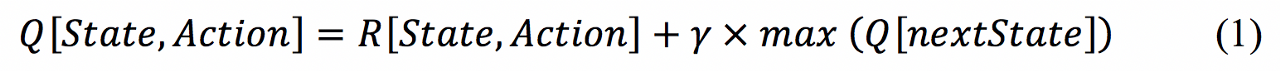
Equation (1) returns a score evaluating the move from one point to a new one. It also takes in consideration any previous scores the model has already seen. The term ‘state’ is the current room the bot is in, and ‘action’ is the next state or next room. is a tunable variable between 0 and 1 where values closer to 0 make the model choose an immediate reward while values closer to 1 will consider alternative paths and allow rewards from later moves. Finally, it multiplies gamma against all experienced next actions from the Q-matrix. This is an important part as all new actions take in consideration previous lessons learned.
To understand how this works, let’s take a slight detour, and imagine that our factory has only 5 rooms as shown in the Figure 2:
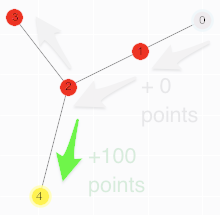
Figure 2: All paths are initialized to 0 except for paths
leading to the goal point which is set to 100 (room 2 to room 4 and recursively
room 4 to room 2).
Below is the matrix format of the rewards table (-1s are used to fill non-existing paths which the bot will ignore):
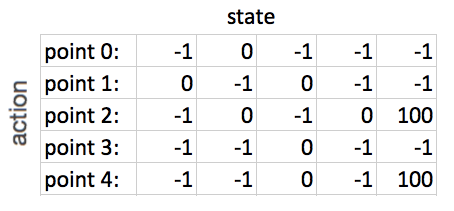
Figure 3:Reward matrix with path and goal-point scores.
The Q-matrix is the same size as the rewards matrix but all cells are initialized with zeros. For n many iterations, the model will randomly select a state, a point on the map represented by a row on the rewards matrix, then move to another state and calculate the rewards for that action. For example, say the model picks point 2 as a state, it can go to either points 1, 3 or 4. According to the rewards matrix, the bot is on row 2 (third from top) and the only cells that aren’t -1s are 1, 3 and 4. Point 4 is chosen at random. According to the Q-Learning algorithm, the score for this move is the current point, plus gamma times maximum value of the new action points:
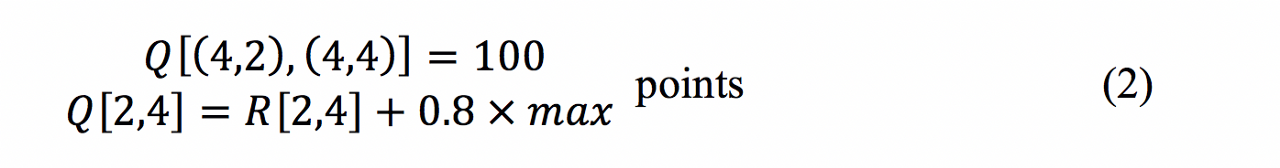
That move is valued at 100 points and entered into the Q-matrix. Why 100? Gamma multiplied by max(Q[(4,2),(4,4)]) equals zero as the bot hasn’t visited those rooms yet and our Q-matrix still only holds zeros. Because as that is the value in R[2,4] and. Had the model chosen point 3 instead, then:
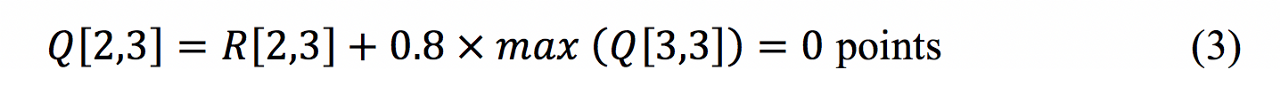
After running the model for few hundred iterations, the model converges and returns the following matrix:
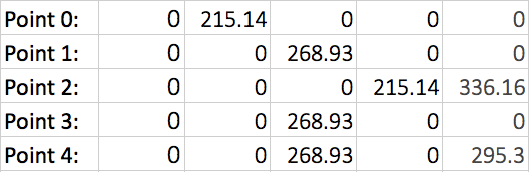
Figure 4: Q-Matrix with converged scores from
learning process.
The matrix shows that starting from point 0 (row 0/room 0), the next step with the highest score is room 1 at 215.14 points. Moving down to the second row, room 3 has the highest score at 268.93 points. Finally, dropping to the third row, room 4 has the highest score, at 336.16 points, which is the goal point. But you can also pick any point you want and find the best path to the goal point from that vantage point (for example starting from room/point 3).
Let’s get back to our factory incident. We had to take this detour as the matrices for our factory are just too big to display and hopefully will be easier to understand. We now let the bot run loose over the factory floor.
Hi there, this is Manuel Amunategui- if you're enjoying the content, find more at ViralML.com
Setting up Q-Learning at a high level
- Rewards Table: Create the rewards table based on a map and the starting and goal points desired.
- Q Table: Initialize the Q-Learning matrix using same dimensions as the rewards matrix and set all cells to 0.
- Discount Factor: Choose a gamma score between 0 and 1, somewhere in the middle so that it doesn't always go for the immediate reward. We set it to 0.8 in this example.
- Iterations: Determine the number of trips to run. This is based on the size of the map (larger maps will require more iterations). We selected 3000 iterations for our factory floor and the corresponding GitHub code uses an early breakout function to stop iterating once it finds the ideal path.
Q-Learning in action
- Select a random starting state (a random room in the factory).
- Select a random next action from the available next actions.
- Calculate maximum Q value for next state (Q[state, action] = R[state, action] + gamma * max(Q[nextState,]) and update the Q-matrix.
- Set next state as current state.
- Keep iterating unless the early-stop function confirms optimal path or runs out of iterations.
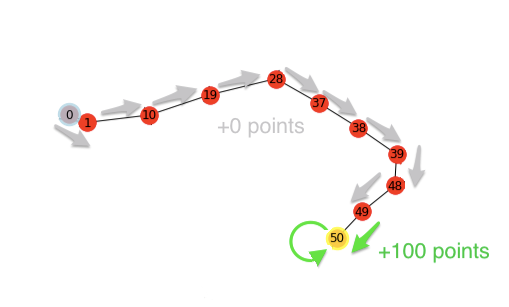
Figure 5: Shows the optimized path and reward points to go from the factory entrance to the chemical's leak.
Once the model runs through its iterations, the model converges and the Q values stabilize.
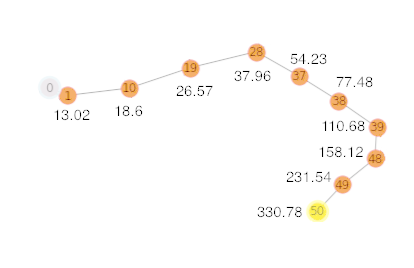
Figure 6: Shows the Q scores for the optimal path from the
factory entrance to the chemical leak.
The Q-Learning model is outfitted with an early-stop feature that will compare the optimal path to the latest Q scores. If the Q scores confirm the optimal path for at least 10 iterations, the model ends automatically. This allows setting large iterations values without being forced to run through them all.
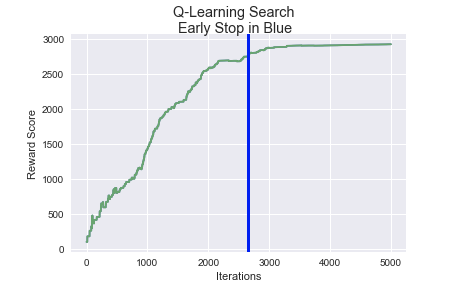
Figure 7: Chart shows the model’s iterations, rising score
and convergence. Blue line shows early-stop feature.
The model successfully converges, finds the optimal path from the entrance of the factory to the goal point, i.e. the chemical leak. The early-stop mechanism stops the model around 2700 iterations.
Part 2: Analysis of Environmental Data: Using Enhanced Q-Learning with Case-based reasoning (CBR)
Now, let’s learn from past data to improve on shortest path to chemical leak. After the robot finds the leak, any additional recorded data can be downloaded and analyzed in order to learn what happened and what were the conditions surrounding the leak beyond humidity readings. The hope is to glean information to help the robot get to the leak faster the next time around.
You could easily analyze that data with a linear-regression model to find patterns using paths, time, or distance against the additional collected features.
In this hypothetical story, after analyzing the data, a correlation emerges between temperature and proximity to the leak - the closer the bot got to the leak, the hotter it got. The thicker blue lines represent a 1-degree temperature jump, the yellow, a 2-degree jump and red, a 5-degree jump.
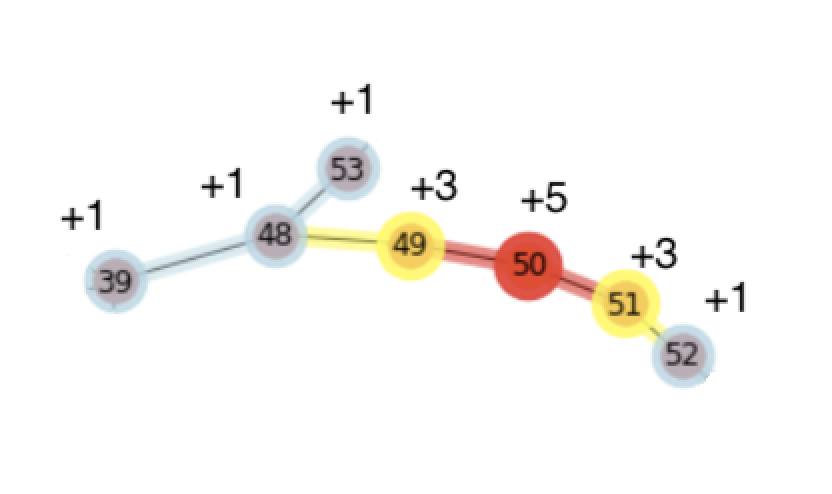
Figure 8: Temperature differentials on the factory
floor — red for hot, yellow for warm and blue for tepid.
Even though this data didn’t help the first emergency scenario or speed up the bot’s iteration process to find the shortest path to the leak, it could prove useful in future similar scenarios. The bot can use the temperature information to spend more time on some routes and ignore others.
We create a similar factory map with the same story of a chemical leak but this time with an understanding of the leak/temperature relationship. The closer we get to the leak, the hotter it should get. We fire off the bot using an enhanced Q-Learning algorithm using the principles behind Case-based reasoning (CBR). The software needs to account for historical similarities with previous cases and use any additional hints it has gleaned in the past to help new searches. In this current situation, it will favor steps with increasing temperatures versus steps with decreasing or non-changing ones. There are a few ways of approaching this in Q-Learning. We could change the rewards map directly to account for this ‘enhanced’ reward data or simply encourage the bot to take routes with increasing temperatures whenever faced with multiple path choices, in this case, we go with the latter. Whenever the bot has to choose between multiple routes, we give more weight to any with rising temperature.
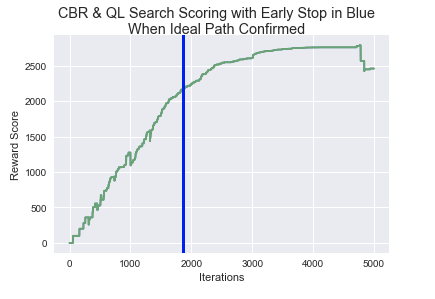
Figure 9: The RL bot took less than 1800 tries to confirm
the ideal path from the factory entrance to the leak with CBR.
You may need to run both examples a couple of times in order to see this pattern emerge. Overall, it takes the CBR-enhanced model almost 1000-less iterations to find the ideal path over the original scenario. This is a toy problem but the ramifications of using RL to map areas along with the ability of recording additional data are real. Even though the immediate use of this additional data may not be apparent, with a little post-processing, it could open up additional and incredible possibilities. This is like unsupervised learning where we don’t quite know what we’re going to get but we want it regardless. In this day of Internet of Things (IoT), it is best to record all available information on the suspicion that it may be useful in the future - because that one day, it may cure disease, save humanity from famine, or help the bot find the chemical leak a little faster.
Note: Companion code found at (https://github.com/amunategui/Leak-At-Chemical-Factory-RL)
Special Thanks
Special thanks to Dr. Mehdi Roopaei for content and edits, Lucas Amunategui for artwork, and Mic’s blog post (http://firsttimeprogrammer.blogspot.com/2016/09/getting-ai-smarter-with-q-learning.html) for easy to digest code on RL.
Manuel Amunategui - Follow me on Twitter: @amunategui