

About Manuel Amunategui
Data scientist with over 20-years experience in the tech industry, MAs in Predictive Analytics and
International Administration, co-author of Monetizing Machine Learning and VP of Data Science at SpringML.
From consulting in machine learning, healthcare modeling, 6 years on Wall Street in the financial industry, and 4 years at Microsoft, I feel like I’ve seen it all. And this has opened my eyes to the huge gap in educational material on applied data science. Like I say:
It just ain’t real 'til it reaches your customer’s plate
I am a startup advisor and available for speaking engagements with companies and schools on topics around building and motivating data science teams, and all things applied machine learning.
Reach me at amunategui@gmail.com


|

Anomaly Detection: Increasing Classification Accuracy with H2O's Autoencoder and R
Practical walkthroughs on machine learning, data exploration and finding insight.

Resources
Packages Used in this Walkthrough
- {h2o}: R Interface for H2O
- {randomForest}: Breiman and Cutler's Random Forests for Classification and Regression
- {pROC} - Display and Analyze ROC Curves
Introduction
- Anomaly Detection
- H2O on AWS
- Let's code!
- Benchmark Random Forest Model
- Autoencoder
- Modeling With and Without Anomalies
Let’s apply H2O’s anomaly detection to separate a data set into easy and hard to model subsets and attempt to gain predictive accuracy.
For those who don’t know yet, H2O is an open-source software for machine learning and big-data analysis. It offers various models such as GLM, GBM and Random Forest, but more importantly, offers a deep learning neural network and large-scale clustering!
For a great introduction to numerous features check out: DeepLearning_Vignette.pdf
Anomaly Detection
Anomaly detection (or outlier detection) is the identification of items, events or observations which do not conform to an expected pattern or other items in a dataset - Wikipedia.com
Anomaly Detection is a big scientific domain, and with such big domains, come many associated techniques and tools. The autoencoder is one of those tools and the subject of this walk-through. H2O offers an easy to use, unsupervised and non-linear autoencoder as part of its deeplearning model. Autoencoding mostly aims at reducing feature space in order to distill the essential aspects of the data versus more conventional deeplearning which blows up the feature space up to capture non-linearities and subtle interactions within the data. Autoencoding can also be seen as a non-linear alternative to PCA.
Here is an interesting video from Arno Candel, the Chief Architect of H2O.ai, Anomaly Detection and Feature Engineering using the MINST data set.
H2O on AWS
I will use H2O on Amazon Web Services (AWS) as it is both trivial to set up and advantageous to your research (H2O supports cluster computing for distributed tasks). In the video, I quickly set up a new H2O Amazon Web Service (AWS) instance but won’t cover it here as it is fully covered in my previous walk-through and video entitled H2O & RStudio Server on Amazon Web Services (AWS), the Easy Way!.
Let's code!
First thing we need to do once we have RStudio up and running is to install H2O:
install.packages("h2o")
In the output pane during the installation of H2O, you will see:
## prostate html
This is the data set we will use to run our models. Let’s go get it and assign it to prostate_df:
# point to the prostate data set in the h2o folder - no need to load h2o in memory yet
prosPath = system.file("extdata", "prostate.csv", package = "h2o")
prostate_df <- read.csv(prosPath)
# We don't need the ID field
prostate_df <- prostate_df[,-1]
summary(prostate_df)
## CAPSULE AGE RACE DPROS
## Min. :0.0000 Min. :43.00 Min. :0.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:62.00 1st Qu.:1.000 1st Qu.:1.000
## Median :0.0000 Median :67.00 Median :1.000 Median :2.000
## Mean :0.4026 Mean :66.04 Mean :1.087 Mean :2.271
## 3rd Qu.:1.0000 3rd Qu.:71.00 3rd Qu.:1.000 3rd Qu.:3.000
## Max. :1.0000 Max. :79.00 Max. :2.000 Max. :4.000
## DCAPS PSA VOL GLEASON
## Min. :1.000 Min. : 0.30 Min. : 0.00 Min. :0.000
## 1st Qu.:1.000 1st Qu.: 5.00 1st Qu.: 0.00 1st Qu.:6.000
## Median :1.000 Median : 8.75 Median :14.25 Median :6.000
## Mean :1.108 Mean : 15.41 Mean :15.81 Mean :6.384
## 3rd Qu.:1.000 3rd Qu.: 17.12 3rd Qu.:26.45 3rd Qu.:7.000
## Max. :2.000 Max. :139.70 Max. :97.60 Max. :9.000
Hi there, this is Manuel Amunategui- if you're enjoying the content, find more at ViralML.com
Benchmark Random Forest Model
Let’s start by running a simple random forest model on the data by splitting it in two random portions (with a seed) - a training and a testing portion. This will give us a base score to measure our improvements using autoencoding.
set.seed(1234)
random_splits <- runif(nrow(prostate_df))
train_df <- prostate_df[random_splits < .5,]
dim(train_df)
## [1] 193 8
validate_df <- prostate_df[random_splits >=.5,]
dim(validate_df)
## [1] 187 8
Install packages randomForest and pROC and run a simple classification model on outcome variable CAPSULE:
install.packages('randomForest')
library(randomForest)
outcome_name <- 'CAPSULE'
feature_names <- setdiff(names(prostate_df), outcome_name)
set.seed(1234)
rf_model <- randomForest(x=train_df[,feature_names],
y=as.factor(train_df[,outcome_name]),
importance=TRUE, ntree=20, mtry = 3)
validate_predictions <- predict(rf_model, newdata=validate_df[,feature_names], type="prob")
Let’s use the pROC library to calculate our AUC score (remember, an AUC of 0.5 is random and 1 is perfect) and plot a chart:
install.packages('pROC')
library(pROC)
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=validate_predictions[,2])
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
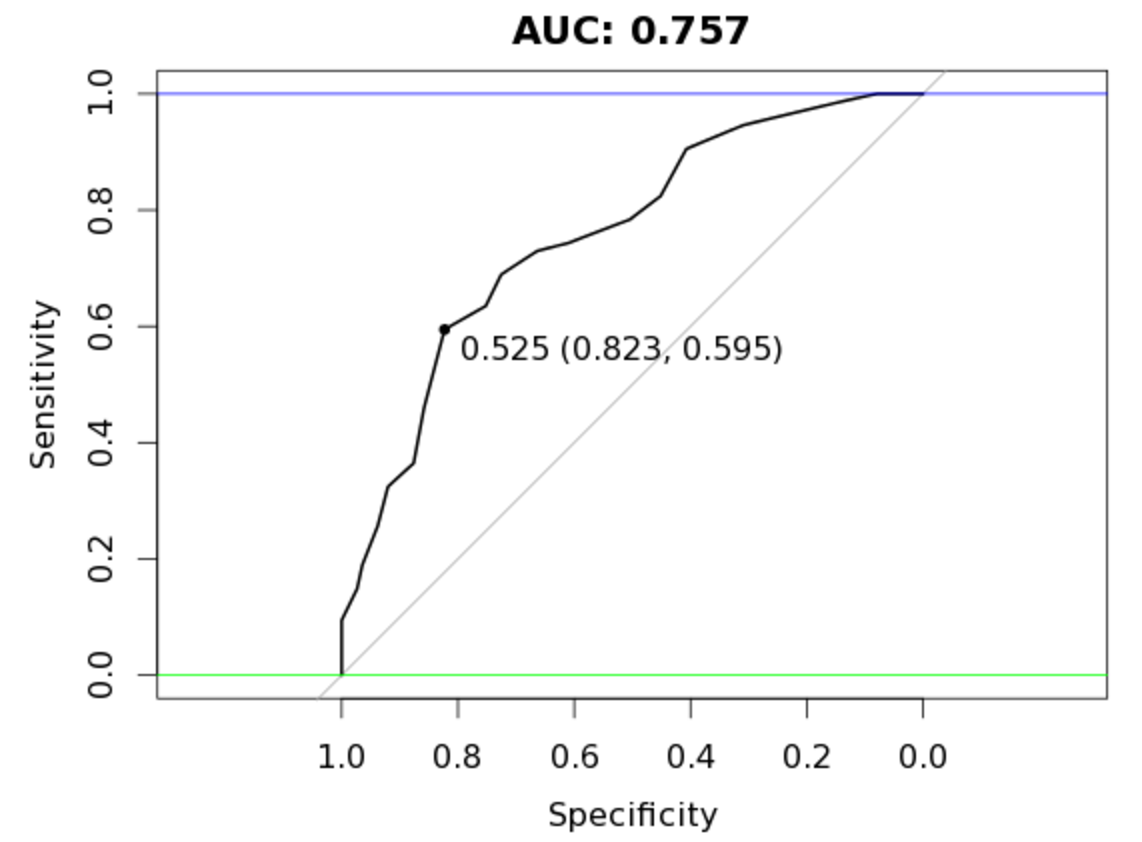
We get an AUC of 0.757 with our current data split.
Autoencoder
Let’s see how an unsupervised autoencoding can assist us here. Start by initializing an h2o instance and create an H2O frame from the prostate data set:
library(h2o)
localH2O = h2o.init()
prostate.hex<-as.h2o(train_df, destination_frame="train.hex")
Getting down to the heart of our business, let’s call the deeplearning function with parameter autoencoder set to TRUE (we also set the reproducible flag to TRUE along with a seed so we all see the same results but this is substantially slower than setting the flag to FALSE):
prostate.dl = h2o.deeplearning(x = feature_names, training_frame = prostate.hex,
autoencoder = TRUE,
reproducible = T,
seed = 1234,
hidden = c(6,5,6), epochs = 50)
We now call the h2o.anomaly function to reconstruct the original data set using the reduced set of features and calculate a means squared error between both. Here we set per_feature parameter to FALSE in the h2o.anomaly function call as we want a reconstruction meany error based on observations, not individual features (but you should definitely play around feature-level scores as it could lead to important insights into your data).
# prostate.anon = h2o.anomaly(prostate.dl, prostate.hex, per_feature=TRUE)
# head(prostate.anon)
prostate.anon = h2o.anomaly(prostate.dl, prostate.hex, per_feature=FALSE)
head(prostate.anon)
err <- as.data.frame(prostate.anon)
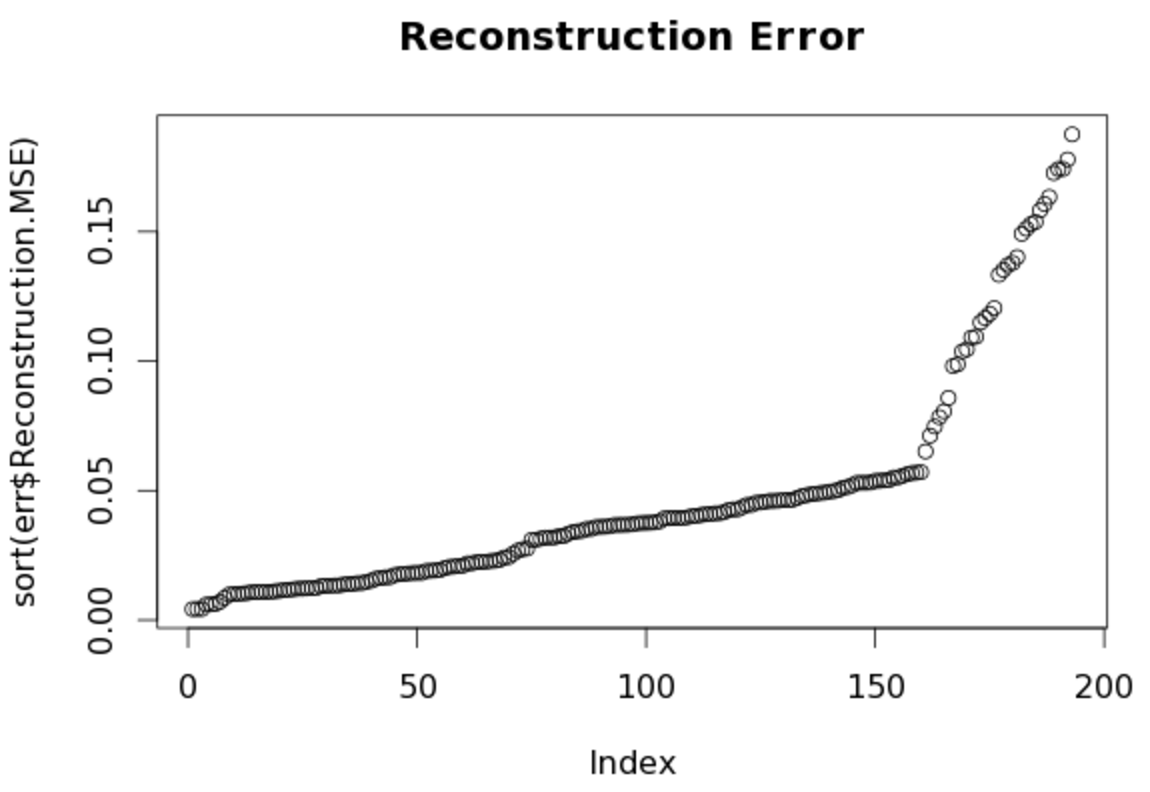
Let’s sort and plot the reconstructed MSE. The autoencoder struggles from index 150 onwards as the error count accelerates upwards. We can determine that the model recognizes patterns in the first 150 observations that it can’t see as easily in the last 50.
plot(sort(err$Reconstruction.MSE), main='Reconstruction Error')
Modeling With and Without Anomalies
The next logical step is to use the clean observations, those that the autoencoder reconstructed easily and model that with our random forest model. We use the err’s Reconstruction.MSE vector to gather everything all observations in our prostate data set with an error below 0.1:
# rebuild train_df_auto with best observations
train_df_auto <- train_df[err$Reconstruction.MSE < 0.1,]
set.seed(1234)
rf_model <- randomForest(x=train_df_auto[,feature_names],
y=as.factor(train_df_auto[,outcome_name]),
importance=TRUE, ntree=20, mtry = 3)
validate_predictions_known <- predict(rf_model, newdata=validate_df[,feature_names], type="prob")
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=validate_predictions_known[,2])
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
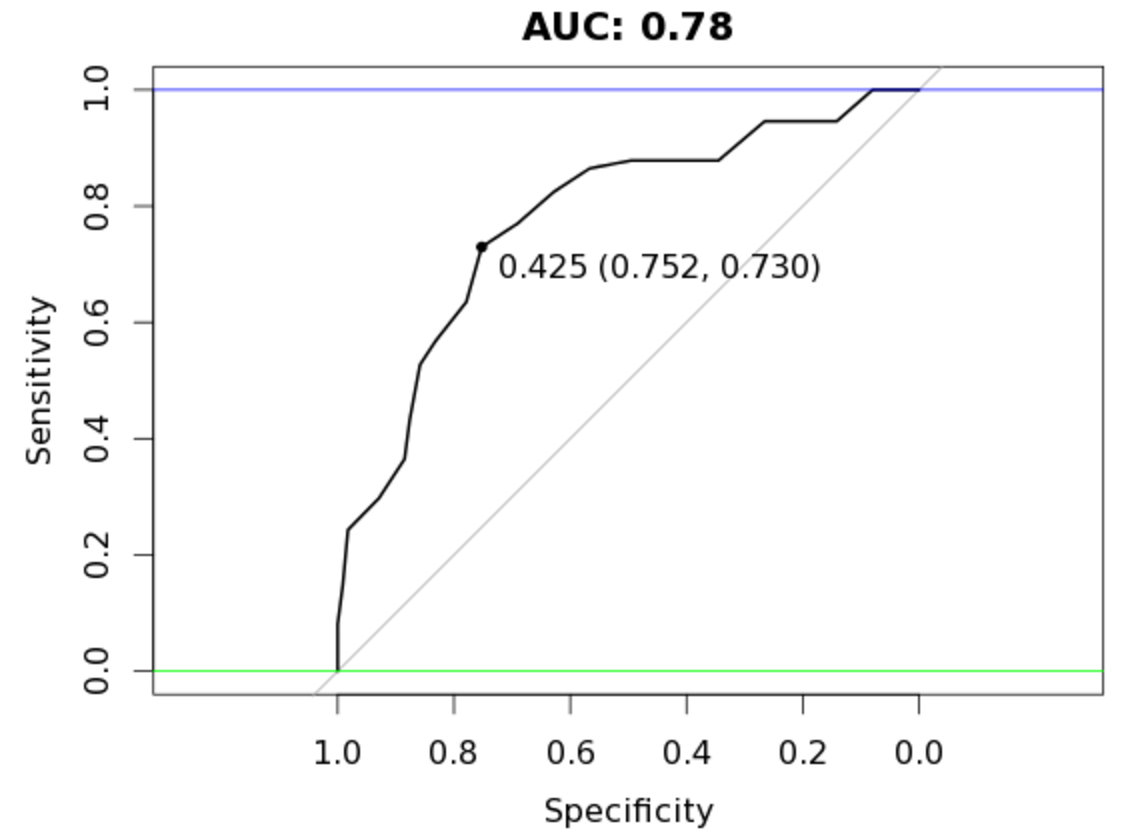
An AUC of 0.78, an improvement over our original random forest model of 0.757 while using less observations!
Let’s try the same model on the hard to reconstruct portion:
# rebuild train_df_auto with best observations
train_df_auto <- train_df[err$Reconstruction.MSE >= 0.1,]
set.seed(1234)
rf_model <- randomForest(x=train_df_auto[,feature_names],
y=as.factor(train_df_auto[,outcome_name]),
importance=TRUE, ntree=20, mtry = 3)
validate_predictions_unknown <- predict(rf_model, newdata=validate_df[,feature_names], type="prob")
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=validate_predictions_unknown[,2])
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
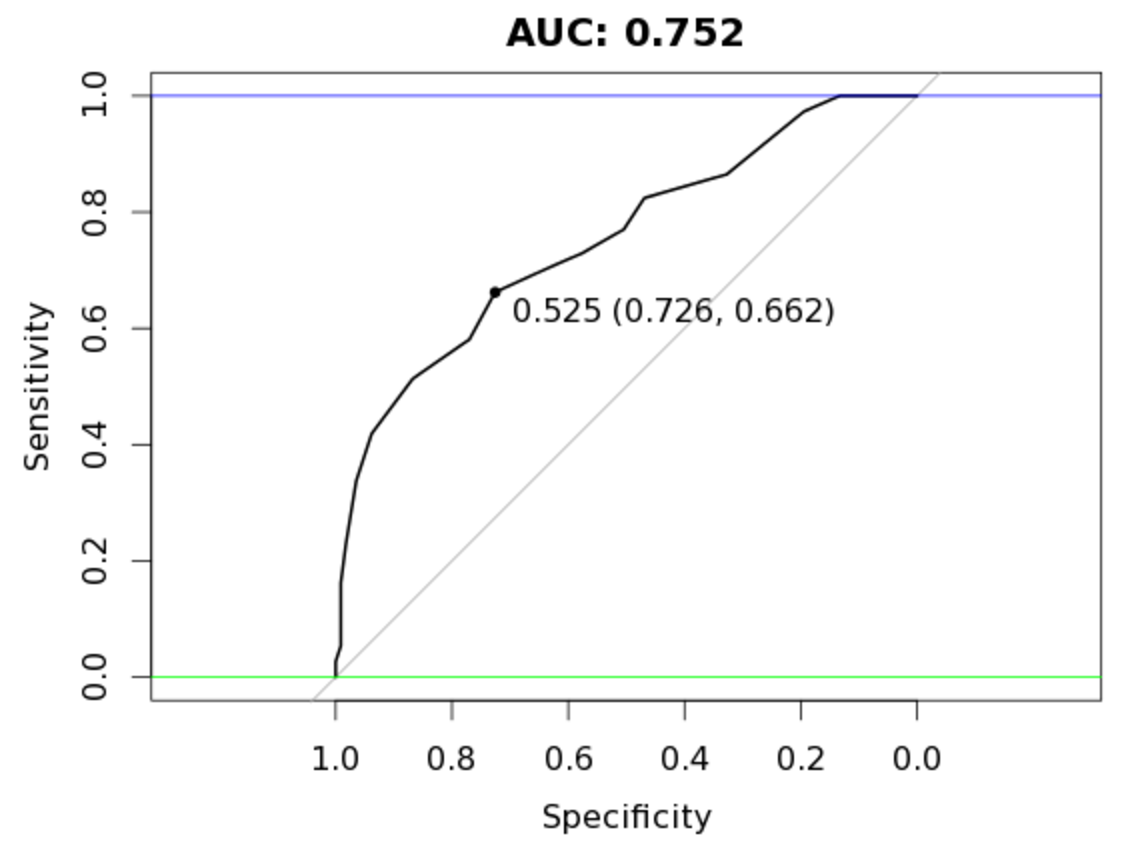
It should be clear by now that these top portions behave very differently under the same model. What about bagging both prediction sets (adding both prediction vectors together and dividing the total by two)?
valid_all <- (validate_predictions_known[,2] + validate_predictions_unknown[,2]) / 2
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=valid_all)
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
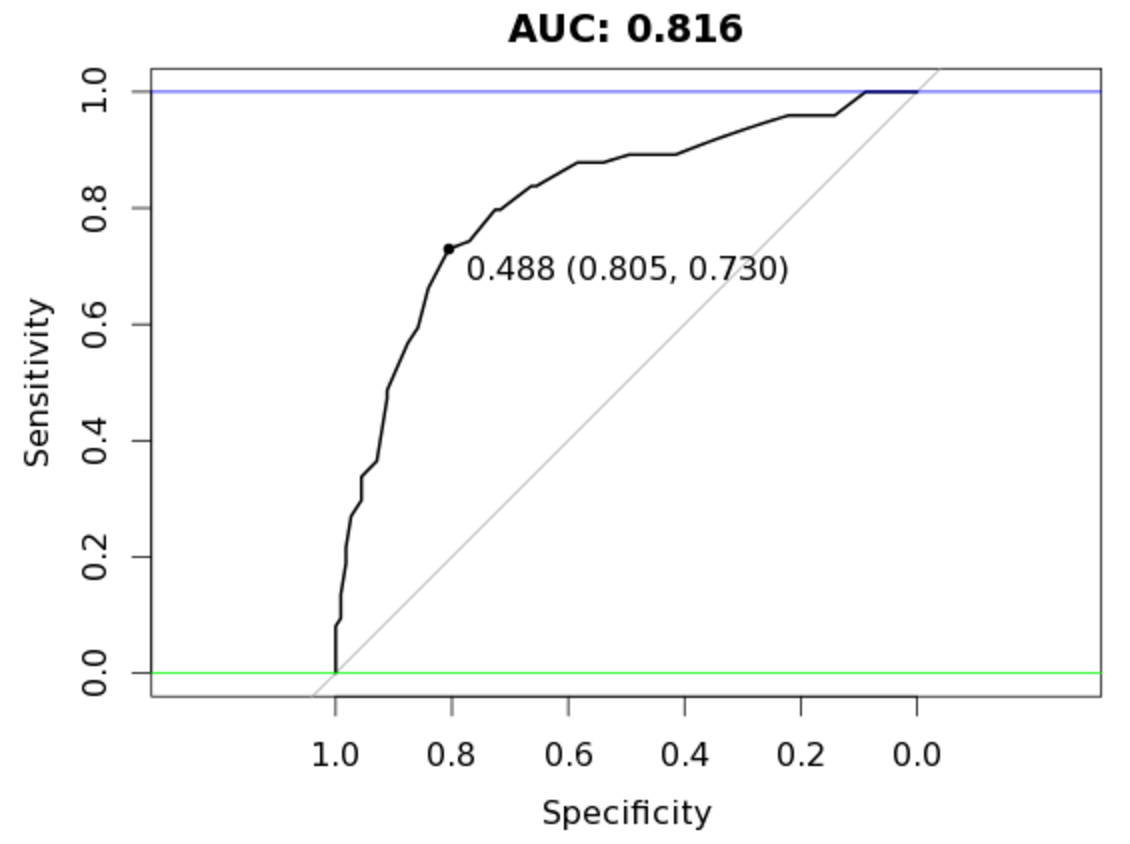
Tremendous! We end up with an AUC of 0.816!! Awesome! In this case, random forest benefitted from the splitting of our data set into two groups of varying patterns. In essence it managed to create better trees for each type which it couldn’t do with the larger original set. Mind you, this doesn’t always pan out this way - a lot has to do on the type of data you are dealing with and the modeling algorithms.
Note: H2O is a fast moving development project, so if certain aspects of this walk-through don’t work, check the documentation for changes in the library.
A special thanks to Lucas A. for the autoencoding fist artwork!
Full source code:
# install.packages("h2o")
# point to the prostate data set in the h2o folder - no need to load h2o in memory yet
prosPath = system.file("extdata", "prostate.csv", package = "h2o")
prostate_df <- read.csv(prosPath)
# We don't need the ID field
prostate_df <- prostate_df[,-1]
summary(prostate_df)
set.seed(1234)
random_splits <- runif(nrow(prostate_df))
train_df <- prostate_df[random_splits < .5,]
dim(train_df)
validate_df <- prostate_df[random_splits >=.5,]
dim(validate_df)
# Get benchmark score
# install.packages('randomForest')
library(randomForest)
outcome_name <- 'CAPSULE'
feature_names <- setdiff(names(prostate_df), outcome_name)
set.seed(1234)
rf_model <- randomForest(x=train_df[,feature_names],
y=as.factor(train_df[,outcome_name]),
importance=TRUE, ntree=20, mtry = 3)
validate_predictions <- predict(rf_model, newdata=validate_df[,feature_names], type="prob")
# install.packages('pROC')
library(pROC)
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=validate_predictions[,2])
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
# build autoencoder model
library(h2o)
localH2O = h2o.init()
prostate.hex<-as.h2o(train_df, destination_frame="train.hex")
prostate.dl = h2o.deeplearning(x = feature_names, training_frame = prostate.hex,
autoencoder = TRUE,
reproducible = T,
seed = 1234,
hidden = c(6,5,6), epochs = 50)
# interesting per feature error scores
# prostate.anon = h2o.anomaly(prostate.dl, prostate.hex, per_feature=TRUE)
# head(prostate.anon)
prostate.anon = h2o.anomaly(prostate.dl, prostate.hex, per_feature=FALSE)
head(prostate.anon)
err <- as.data.frame(prostate.anon)
# interesting reduced features (defaults to last hidden layer)
# http://www.rdocumentation.org/packages/h2o/functions/h2o.deepfeatures
# reduced_new <- h2o.deepfeatures(prostate.dl, prostate.hex)
plot(sort(err$Reconstruction.MSE))
# use the easy portion and model with random forest using same settings
train_df_auto <- train_df[err$Reconstruction.MSE < 0.1,]
set.seed(1234)
rf_model <- randomForest(x=train_df_auto[,feature_names],
y=as.factor(train_df_auto[,outcome_name]),
importance=TRUE, ntree=20, mtry = 3)
validate_predictions_known <- predict(rf_model, newdata=validate_df[,feature_names], type="prob")
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=validate_predictions_known[,2])
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
# use the hard portion and model with random forest using same settings
train_df_auto <- train_df[err$Reconstruction.MSE >= 0.1,]
set.seed(1234)
rf_model <- randomForest(x=train_df_auto[,feature_names],
y=as.factor(train_df_auto[,outcome_name]),
importance=TRUE, ntree=20, mtry = 3)
validate_predictions_unknown <- predict(rf_model, newdata=validate_df[,feature_names], type="prob")
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=validate_predictions_unknown[,2])
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
# bag both results set and measure final AUC score
valid_all <- (validate_predictions_known[,2] + validate_predictions_unknown[,2]) / 2
auc_rf = roc(response=as.numeric(as.factor(validate_df[,outcome_name]))-1,
predictor=valid_all)
plot(auc_rf, print.thres = "best", main=paste('AUC:',round(auc_rf$auc[[1]],3)))
abline(h=1,col='blue')
abline(h=0,col='green')
Manuel Amunategui - Follow me on Twitter: @amunategui