

About Manuel Amunategui
Data scientist with over 20-years experience in the tech industry, MAs in Predictive Analytics and
International Administration, co-author of Monetizing Machine Learning and VP of Data Science at SpringML.
From consulting in machine learning, healthcare modeling, 6 years on Wall Street in the financial industry, and 4 years at Microsoft, I feel like I’ve seen it all. And this has opened my eyes to the huge gap in educational material on applied data science. Like I say:
It just ain’t real 'til it reaches your customer’s plate
I am a startup advisor and available for speaking engagements with companies and schools on topics around building and motivating data science teams, and all things applied machine learning.
Reach me at amunategui@gmail.com


|

Find Variable Importance for any Model - Prediction Shuffling with R
Practical walkthroughs on machine learning, data exploration and finding insight.
Resources
Packages Used in this Walkthrough
- {caret} - Classification and Regression Training
- {mRMRe} - R package for parallelized mRMR ensemble feature selection
My colleague showed me a nifty concept to easily calculate variable importance for any model. He did not invent it, actually many forms of it abound in the literature and on the Internet. John Elder is one of the authors.
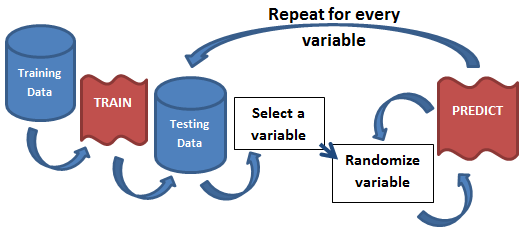
The idea is so simple, its brilliant; you model once, predict once to get a benchmark score, and finally predict hundreds of times for each variable in the model while randomizing that variable. If the variable being randomized hurts the model’s benchmark score, then its an important variable. If, on the other hand, nothing changes, or it beats the benchmark, then its a useless variable. By running this hundreds of times for each variable, you can paint a clear picture of what variable is affecting the model and to what degree. The beauty of this approach is that it is model agnostic as everything happens after the modeling phase.
Let’s code!
We’ll use the good old Titanic dataset from the University of Colorado Denver that I’ve used in many of my walkthroughs. This is a classic data set often seen in online courses and walkthroughs. The outcome is passenger survivorship (i.e. can you predict who will survive based on various features). We drop the passenger names as they are all unique but keep the passenger titles. We also impute the missing ‘Age’ variables with the mean and binarize all non-numerical data:
# using dataset from the UCI Machine Learning Repository (http://archive.ics.uci.edu/ml/)
titanicDF <- read.csv('http://math.ucdenver.edu/RTutorial/titanic.txt',sep='\t')
# creating new title feature
titanicDF$Title <- ifelse(grepl('Mr ',titanicDF$Name),'Mr',ifelse(grepl('Mrs ',titanicDF$Name),'Mrs',ifelse(grepl('Miss',titanicDF$Name),'Miss','Nothing')))
titanicDF$Title <- as.factor(titanicDF$Title)
# impute age to remove NAs
titanicDF$Age[is.na(titanicDF$Age)] <- median(titanicDF$Age, na.rm=T)
# reorder data set so target is last column
titanicDF <- titanicDF[c('PClass', 'Age', 'Sex', 'Title', 'Survived')]
# binarize all factors
library(caret)
titanicDummy <- dummyVars("~.",data=titanicDF, fullRank=F)
titanicDF <- as.data.frame(predict(titanicDummy,titanicDF))
Let’s take a peek at our data:
str(titanicDF)
## 'data.frame': 1313 obs. of 11 variables:
## $ PClass.1st : num 1 1 1 1 1 1 1 1 1 1 ...
## $ PClass.2nd : num 0 0 0 0 0 0 0 0 0 0 ...
## $ PClass.3rd : num 0 0 0 0 0 0 0 0 0 0 ...
## $ Age : num 29 2 30 25 0.92 47 63 39 58 71 ...
## $ Sex.female : num 1 1 0 1 0 0 1 0 1 0 ...
## $ Sex.male : num 0 0 1 0 1 1 0 1 0 1 ...
## $ Title.Miss : num 1 1 0 0 0 0 1 0 0 0 ...
## $ Title.Mr : num 0 0 1 0 0 1 0 1 0 1 ...
## $ Title.Mrs : num 0 0 0 1 0 0 0 0 1 0 ...
## $ Title.Nothing: num 0 0 0 0 1 0 0 0 0 0 ...
## $ Survived : num 1 0 0 0 1 1 1 0 1 0 ...
Hi there, this is Manuel Amunategui- if you're enjoying the content, find more at ViralML.com
We’ll start by running a simple Gradient Boosted Machine (GBM) model on the data in order to get our benchmark area-under-the-curve (AUC) score. First we need to split the data into a training and testing portion, generalize our outcome and predictor names, and fix the outcome variable for classification:
# split data set into train and test portion
set.seed(1234)
splitIndex <- sample(nrow(titanicDF), floor(0.5*nrow(titanicDF)))
trainDF <- titanicDF[ splitIndex,]
testDF <- titanicDF[-splitIndex,]
outcomeName <- 'Survived'
predictorNames <- setdiff(names(trainDF),outcomeName)
# transform outcome variable to text as this is required in caret for classification
trainDF[,outcomeName] <- ifelse(trainDF[,outcomeName]==1,'yes','nope')
Now we’re ready to run a simple GBM model:
# create caret trainControl object to control the number of cross-validations performed
objControl <- trainControl(method='cv', number=2, returnResamp='none', summaryFunction = twoClassSummary, classProbs = TRUE)
objGBM <- train(trainDF[,predictorNames], as.factor(trainDF[,outcomeName]),
method='gbm',
trControl=objControl,
metric = "ROC",
tuneGrid = expand.grid(n.trees = 5, interaction.depth = 3, shrinkage = 0.1)
)
predictions <- predict(object=objGBM, testDF[,predictorNames], type='prob')
Here I introduce a very fast AUC approximation function found on stackoverflow that will allow us to calculate the AUC thousands of times with minimal processing:
GetROC_AUC = function(probs, true_Y){
# AUC approximation
# http://stackoverflow.com/questions/4903092/calculate-auc-in-r
# ty AGS
probsSort = sort(probs, decreasing = TRUE, index.return = TRUE)
val = unlist(probsSort$x)
idx = unlist(probsSort$ix)
roc_y = true_Y[idx];
stack_x = cumsum(roc_y == 0)/sum(roc_y == 0)
stack_y = cumsum(roc_y == 1)/sum(roc_y == 1)
auc = sum((stack_x[2:length(roc_y)]-stack_x[1:length(roc_y)-1])*stack_y[2:length(roc_y)])
return(auc)
}
refAUC <- GetROC_AUC(predictions[[2]],testDF[,outcomeName])
print(paste('AUC score:', refAUC))
## [1] "AUC score: 0.855016305004227"
Shuffling with GBM
Now we have a benchmark AUC score of 0.85. We will use this score during every iteration of the shuffler to determine the effect of the scrambled variable:
# Shuffle predictions for variable importance
AUCShuffle <- NULL
shuffletimes <- 500
featuresMeanAUCs <- c()
for (feature in predictorNames) {
featureAUCs <- c()
shuffledData <- testDF[,predictorNames]
for (iter in 1:shuffletimes) {
shuffledData[,feature] <- sample(shuffledData[,feature], length(shuffledData[,feature]))
predictions <- predict(object=objGBM, shuffledData[,predictorNames], type='prob')
featureAUCs <- c(featureAUCs,GetROC_AUC(predictions[[2]], testDF[,outcomeName]))
}
featuresMeanAUCs <- c(featuresMeanAUCs, mean(featureAUCs < refAUC))
}
AUCShuffle <- data.frame('feature'=predictorNames, 'importance'=featuresMeanAUCs)
AUCShuffle <- AUCShuffle[order(AUCShuffle$importance, decreasing=TRUE),]
print(AUCShuffle)
## feature importance
## 3 PClass.3rd 1.000
## 5 Sex.female 1.000
## 8 Title.Mr 1.000
## 1 PClass.1st 0.924
## 4 Age 0.866
## 9 Title.Mrs 0.218
## 2 PClass.2nd 0.000
## 6 Sex.male 0.000
## 7 Title.Miss 0.000
## 10 Title.Nothing 0.000
There you have it, by iterating through each variable and scrambling them 200 times, the following 3 variables proved most important:PClass.3rd, Sex.female, Title.Mr.
Let’s put this in words one more time; we started by modeling our Titanic data set once with a GBM model and used the saved model to predict a reference (or benchmark) AUC score. With the saved benchmark and model, we created a loop to cycle through every variable in the set and predict the test set 200 times while scrambling the values of that variable each time.
The above code can easily be used with any other tree-based classifiers such as random forests.
Shuffling with GLM
Now let’s try this with a GLM model. You’ll see that the code is similar except we’ll be using the Root Mean Square Error (RMSE) score instead of an AUC score.
# change a few things for a linear model
objControl <- trainControl(method='cv', number=2)
trainDF[,outcomeName] <- ifelse(trainDF[,outcomeName]=='yes', 1, 0)
# shuffling with GLM
objGLM <- train(trainDF[,predictorNames], trainDF[,outcomeName],
method='glm',
trControl=objControl,
preProc = c("center", "scale"))
predictions <- predict(object=objGLM, testDF[,predictorNames])
refRMSE=sqrt((sum((testDF[,outcomeName]-predictions[[2]])^2))/nrow(testDF))
print(paste('Reference RMSE:',refRMSE))
## [1] "Reference RMSE: 0.4803244"
# Shuffle predictions for variable importance
VariableImportanceShuffle <- NULL
shuffletimes <- 500
featuresMeanRMSEs <- c()
for (feature in predictorNames) {
featureRMSEs <- c()
shuffledData <- testDF[,predictorNames]
for (iter in 1:shuffletimes) {
shuffledData[,feature] <- sample(shuffledData[,feature], length(shuffledData[,feature]))
predictions <- predict(object=objGLM, shuffledData[,predictorNames])
featureRMSEs <- c(featureRMSEs, sqrt((sum((testDF[,outcomeName]-predictions[[2]])^2))/nrow(testDF)))
}
featuresMeanRMSEs <- c(featuresMeanRMSEs, mean((featureRMSEs - refRMSE)/refRMSE))
}
VariableImportanceShuffle <- data.frame('feature'=predictorNames, 'RMSE_Importance'=featuresMeanRMSEs)
VariableImportanceShuffle <- VariableImportanceShuffle[order(VariableImportanceShuffle$RMSE_Importance,decreasing=TRUE),]
print(VariableImportanceShuffle)
## feature RMSE_Importance
## 1 PClass.1st 0.2334582971
## 8 Title.Mr 0.0338742797
## 5 Sex.female 0.0301143113
## 2 PClass.2nd 0.0161501428
## 4 Age 0.0080605542
## 7 Title.Miss 0.0017299712
## 9 Title.Mrs 0.0007030486
## 3 PClass.3rd 0.0000000000
## 6 Sex.male 0.0000000000
## 10 Title.Nothing 0.0000000000
The code is almost the same (except for the scoring formula) but the results are different which is to be expected when using two different models (tree based versus linear).
As a bonus, here is a great package for quick variable importance. I won’t go into any details but I recommend it for its speed!
# bonus - great package for fast variable importance
library(mRMRe)
ind <- sapply(titanicDF, is.integer)
titanicDF[ind] <- lapply(titanicDF[ind], as.numeric)
dd <- mRMR.data(data = titanicDF)
feats <- mRMR.classic(data = dd, target_indices = c(ncol(titanicDF)), feature_count = 10)
variableImportance <-data.frame('importance'=feats@mi_matrix[nrow(feats@mi_matrix),])
variableImportance$feature <- rownames(variableImportance)
row.names(variableImportance) <- NULL
variableImportance <- na.omit(variableImportance)
variableImportance <- variableImportance[order(variableImportance$importance, decreasing=TRUE),]
print(variableImportance)
## importance feature
## 5 0.50289113 Sex.female
## 9 0.35928727 Title.Mrs
## 1 0.30824025 PClass.1st
## 7 0.24287839 Title.Miss
## 2 0.09024881 PClass.2nd
## 10 0.05892875 Title.Nothing
## 4 -0.02888115 Age
## 3 -0.34033536 PClass.3rd
## 8 -0.48448426 Title.Mr
## 6 -0.50289113 Sex.male
Enjoy!!
Full source code (also on GitHub):
# using dataset from the UCI Machine Learning Repository (http://archive.ics.uci.edu/ml/)
titanicDF <- read.csv('http://math.ucdenver.edu/RTutorial/titanic.txt',sep='\t')
# creating new title feature
titanicDF$Title <- ifelse(grepl('Mr ',titanicDF$Name),'Mr',ifelse(grepl('Mrs ',titanicDF$Name),'Mrs',ifelse(grepl('Miss',titanicDF$Name),'Miss','Nothing')))
titanicDF$Title <- as.factor(titanicDF$Title)
# impute age to remove NAs
titanicDF$Age[is.na(titanicDF$Age)] <- median(titanicDF$Age, na.rm=T)
# reorder data set so target is last column
titanicDF <- titanicDF[c('PClass', 'Age', 'Sex', 'Title', 'Survived')]
# binarize all factors
library(caret)
titanicDummy <- dummyVars("~.",data=titanicDF, fullRank=F)
titanicDF <- as.data.frame(predict(titanicDummy,titanicDF))
# Let's take a peek at our data:
str(titanicDF)
# split data set into train and test portion
set.seed(1234)
splitIndex <- sample(nrow(titanicDF), floor(0.5*nrow(titanicDF)))
trainDF <- titanicDF[ splitIndex,]
testDF <- titanicDF[-splitIndex,]
outcomeName <- 'Survived'
predictorNames <- setdiff(names(trainDF),outcomeName)
# transform outcome variable to text as this is required in caret for classification
trainDF[,outcomeName] <- ifelse(trainDF[,outcomeName]==1,'yes','nope')
# create caret trainControl object to control the number of cross-validations performed
objControl <- trainControl(method='cv', number=2, returnResamp='none', summaryFunction = twoClassSummary, classProbs = TRUE)
# shuffling with GBM
objGBM <- train(trainDF[,predictorNames], as.factor(trainDF[,outcomeName]),
method='gbm',
trControl=objControl,
metric = "ROC",
tuneGrid = expand.grid(n.trees = 5, interaction.depth = 3, shrinkage = 0.1)
)
predictions <- predict(object=objGBM, testDF[,predictorNames], type='prob')
GetROC_AUC = function(probs, true_Y){
# AUC approximation
# http://stackoverflow.com/questions/4903092/calculate-auc-in-r
# ty AGS
probsSort = sort(probs, decreasing = TRUE, index.return = TRUE)
val = unlist(probsSort$x)
idx = unlist(probsSort$ix)
roc_y = true_Y[idx];
stack_x = cumsum(roc_y == 0)/sum(roc_y == 0)
stack_y = cumsum(roc_y == 1)/sum(roc_y == 1)
auc = sum((stack_x[2:length(roc_y)]-stack_x[1:length(roc_y)-1])*stack_y[2:length(roc_y)])
return(auc)
}
refAUC <- GetROC_AUC(predictions[[2]],testDF[,outcomeName])
print(paste('AUC score:', refAUC))
# Shuffle predictions for variable importance
AUCShuffle <- NULL
shuffletimes <- 500
featuresMeanAUCs <- c()
for (feature in predictorNames) {
featureAUCs <- c()
shuffledData <- testDF[,predictorNames]
for (iter in 1:shuffletimes) {
shuffledData[,feature] <- sample(shuffledData[,feature], length(shuffledData[,feature]))
predictions <- predict(object=objGBM, shuffledData[,predictorNames], type='prob')
featureAUCs <- c(featureAUCs,GetROC_AUC(predictions[[2]], testDF[,outcomeName]))
}
featuresMeanAUCs <- c(featuresMeanAUCs, mean(featureAUCs < refAUC))
}
AUCShuffle <- data.frame('feature'=predictorNames, 'importance'=featuresMeanAUCs)
AUCShuffle <- AUCShuffle[order(AUCShuffle$importance, decreasing=TRUE),]
print(AUCShuffle)
# shuffling with GLM
# change a few things for a linear model
objControl <- trainControl(method='cv', number=2)
trainDF[,outcomeName] <- ifelse(trainDF[,outcomeName]=='yes', 1, 0)
# GLM
objGLM <- train(trainDF[,predictorNames], trainDF[,outcomeName],
method='glm',
trControl=objControl,
preProc = c("center", "scale"))
predictions <- predict(object=objGLM, testDF[,predictorNames])
refRMSE=sqrt((sum((testDF[,outcomeName]-predictions[[2]])^2))/nrow(testDF))
VariableImportanceShuffle <- NULL
print(paste('Reference RMSE:',refRMSE))
shuffletimes <- 500
featuresMeanRMSEs <- c()
for (feature in predictorNames) {
featureRMSEs <- c()
shuffledData <- testDF[,predictorNames]
for (iter in 1:shuffletimes) {
shuffledData[,feature] <- sample(shuffledData[,feature], length(shuffledData[,feature]))
predictions <- predict(object=objGLM, shuffledData[,predictorNames])
featureRMSEs <- c(featureRMSEs, sqrt((sum((testDF[,outcomeName]-predictions[[2]])^2))/nrow(testDF)))
}
featuresMeanRMSEs <- c(featuresMeanRMSEs, mean((featureRMSEs - refRMSE)/refRMSE))
}
VariableImportanceShuffle <- data.frame('feature'=predictorNames, 'RMSE_Importance'=featuresMeanRMSEs)
VariableImportanceShuffle <-
VariableImportanceShuffle[order(VariableImportanceShuffle$RMSE_Importance,decreasing=TRUE),]
print(VariableImportanceShuffle)
# bonus - great package for fast variable importance
library(mRMRe)
ind <- sapply(titanicDF, is.integer)
titanicDF[ind] <- lapply(titanicDF[ind], as.numeric)
dd <- mRMR.data(data = titanicDF)
feats <- mRMR.classic(data = dd, target_indices = c(ncol(titanicDF)), feature_count = 10)
variableImportance <-data.frame('importance'=feats@mi_matrix[nrow(feats@mi_matrix),])
variableImportance$feature <- rownames(variableImportance)
row.names(variableImportance) <- NULL
variableImportance <- na.omit(variableImportance)
variableImportance <- variableImportance[order(variableImportance$importance, decreasing=TRUE),]
print(variableImportance)
Manuel Amunategui - Follow me on Twitter: @amunategui