

About Manuel Amunategui
Data scientist with over 20-years experience in the tech industry, MAs in Predictive Analytics and
International Administration, co-author of Monetizing Machine Learning and VP of Data Science at SpringML.
From consulting in machine learning, healthcare modeling, 6 years on Wall Street in the financial industry, and 4 years at Microsoft, I feel like I’ve seen it all. And this has opened my eyes to the huge gap in educational material on applied data science. Like I say:
It just ain’t real 'til it reaches your customer’s plate
I am a startup advisor and available for speaking engagements with companies and schools on topics around building and motivating data science teams, and all things applied machine learning.
Reach me at amunategui@gmail.com


|

Chatbot Conversations From Customer Service Transcripts
Practical walkthroughs on machine learning, data exploration and finding insight.
On YouTube:
|
GitHub Code:
| Chatbot-Conversations.ipynb |
Introduction

- Dialogflow.com
Chatbots are all the rage these days and we get a lot of requests for them at SpringML. They not only have that “AI” chic, they’re also offer faster customer service at a much cheaper cost - a huge win-win.
Though chatbot technology is mature and available today, see Dialogflow from Google as an example of how easy it is to implement, building a good one is no trivial task. The last thing you want to do is anger customers that are reaching out for help.
In this blog entry, I’ll walk you through a typical approach to come up with chatbot scenarios that are sensible, realistic and offer added value to both customers and its company as a chatbot service. The key is to get good quality transcripts from the customer service department you want to extend. And it doesn’t have to be just customer service, if its a pizza delivery service, then transcripts of phone orders will work just the same. The goal is to find clusters of questions and issues that we can then generalize into chatbot interactions.
The process to distill transcripts into simple chat bot entities and intents:
- Basic natural language processing (NLP) script cleaning
- Extract important verbs and nouns with parts of speech (POS) tools
- Clustering scripts by key verbs and nouns
- Running ngrams on clusters to infer entity and intent
Hi there, this is Manuel Amunategui- if you're enjoying the content, find more at ViralML.com
Chatbot 101
For a great yet simple look at Dialogflow video, I recommend the YouTube video: https://www.youtube.com/watch?v=gWNUg_v25dw
In a nutshell, you have:
- Entities: these are objects or things your bot is taking action on and needs to recognize - in the video above on the pizza delivery bot, entities are toppings like onions, pepperoni, etc.
- Intent: things the user will say: “I am hungry”, “I want to order a pizza”, “pizza for pickup”, etc.
- Answers to intent: scenario responses you need to come up with and the subject of this blog post, like "what type of pizza do you want?”
In Dialogflow (https://dialogflow.com) you can create all the above and integrate it to Slack, Facebook Messenger, Skype, etc, all within its web-based dashboard. This is great for quick prototypes.
Consumer Complaint Database From The Bureau of Consumer Financial Protection (CFPB)
“These are complaints we’ve received about financial products and services.”[1]
- CFBP
As an example of a realistic customer service data set, we will use the publicly-available “Consumer Complaint Database” from the Bureau of Consumer Financial Protection (CFPB) made available on the Data.gov website. Of interest for this blog post is the “Consumer complaint narrative” feature that contains over 200k worth of complaint narratives.
complaints_df_raw.head()
The CSV link changes over time so go to: https://catalog.data.gov/dataset/consumer-complaint-database and pick one of the comma delimited files to follow along.
NLP Basic Cleanup
The NLP cleanup phase isn’t special but necessary. We parse each customer complaint and remove the following (see the code for further details):
- Null complaints and products
- Duplicate complaints
- Anonymizing characters
- Special characters
- Complaints with too much repeated information
We also force everything to lower-case, though this could be left as the spaCy library may make use of capital letters to determine word types.
Part-of-speech (POS): Finding Top Verbs And Nouns
This really is the trick we are going to use to parse large bodies of text and pick up on patterns in the transcripts. We will leverage the spaCy Python library (https://spacy.io), self-described as an “Industrial-Strength, Natural Language Processing” library - which it is.
This NLP library has so much to offer but here we will focus only on the Part-of-speech (POS) parser [2].
After tokenization, spaCy can parse and tag a given Doc. This is where the statistical model comes in, which enables spaCy to make a prediction of which tag or label most likely applies in this context. A model consists of binary data and is produced by showing a system enough examples for it to make predictions that generalise across the language – for example, a word following "the" in English is most likely a noun.
- spaCy docs
We are interested in its ability to tag the nouns and verbs within each customer complaint. Here is a sample of the top ones spaCy picked up:
just_verbs[0].split()[0:10]
['approve',
'decline',
'have',
'is',
'have',
'spoke',
'being',
'reported',
'do',
'know']
just_nouns[0].split()[0:10]
['computer',
'base',
'system',
'pre',
'credit',
'limit',
'applicationi',
'dept',
'credit',
'report']
Once we have the harvested all the nouns and verbs from spaCy, we run frequency counts and pull the most frequents.
# what is your upper and lower cut offs?
from collections import Counter
verbs_df = pd.DataFrame(Counter([verb for verb in verbs_master]).most_common(), columns = ['verb', 'count'])
verbs_df.head(20)
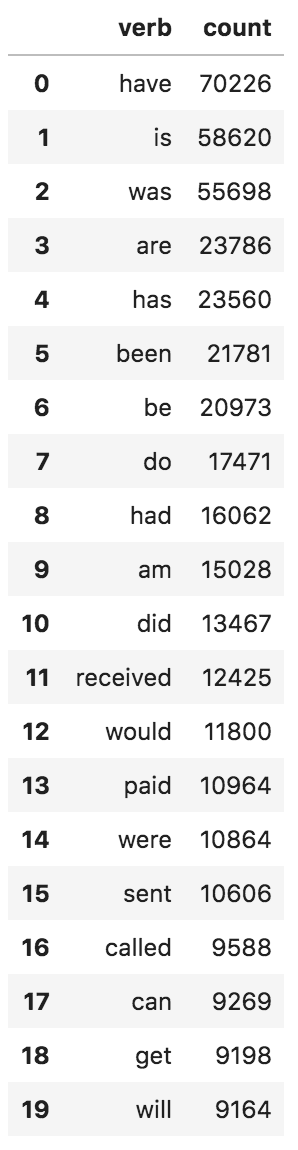
The cutoffs for both categories are subjective and require experimentation depending on the richness of the harvested words found in the transcripts.
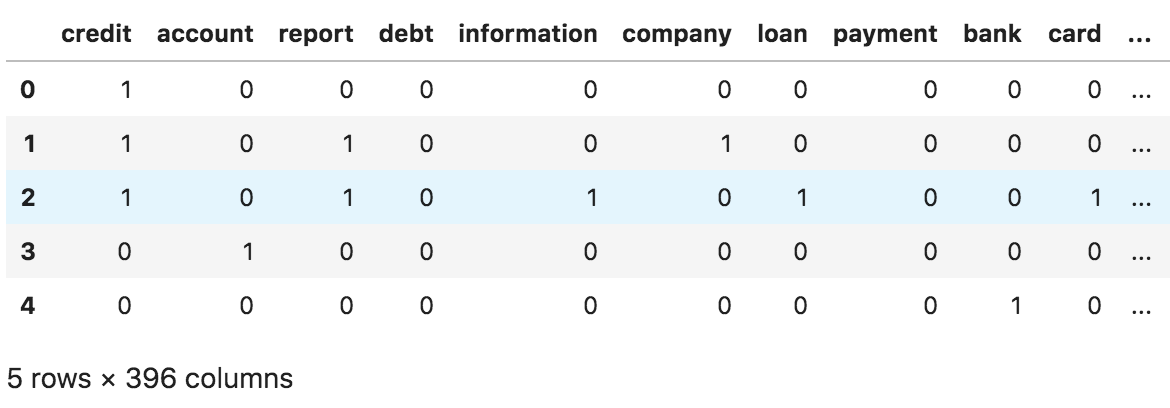
The final step before clustering the data is to binarize our chosen words. This entails creating a complaint dataframe with each selected word as a feature.
row_bools.head()
Clustering Based On Keywords
Now that we have our dataframe of chosen key words ready, we can run some Sklearn clusters!
from sklearn.cluster import KMeans
TOTAL_CLUSTERS = 50
# Number of clusters
kmeans = KMeans(n_clusters=TOTAL_CLUSTERS)
# Fitting the input data
kmeans = kmeans.fit(row_bools)
# Getting the cluster labels
labels = kmeans.predict(row_bools)
# add cluster back to data frame
row_bools['cluster'] = labels
row_bools['cluster'].value_counts().head()

Obviously, there are no rules to cluster size, it could be based on the number of questions you want your chatbot to handle or the richness and complexity of the customer transcript data. A lot of experimentation is required.
N-grams Per Cluster
This is the final phase of the process before the manual analysis and extraction process begins. We leverage the NLTK library to pull all the n-grams we need.
N-grams are sequences of varying sizes found in the text. For example,
“The rabbit is running”
Has the following 3 ngrams of 2 dimensions (bigrams):
- The rabbit
- rabbit is
- is running
The reason we are using this approach is to find now many times certain sequential word patterns are used in different complaints (clustered-complaints in our case). The hope is to translate similar complaints into chatbot scenarios that will handle common calls. In our consumer complaint data, we will run n-grams of dimension 2, 3, 4, 5, 6. The larger, the more revelatory to find complex and repeated patterns.
Here is a look at a sample of 6-grams from cluster 47:

A Chatbot Intent
Clearly, the customer is reporting a complaint that a debt collector is trying to pin on them. We can easily then pull a promising samples from the above list to craft a chatbot scenario script.
# tie it back to look into a couple of actual complaints
keywords = "attempting to collect a debt from"
for index, row in complaints_df.iterrows():
txt = row['Consumer complaint narrative']
if (keywords in txt):
print(txt)
print('------')
“wakefield and associates of , colorado, has been attempting to collect a debt from me for one year. i have never received proof of the debt in writing they have called me multiple times during the day and evening. they have argued with me and have said they do not need to send paper proof of debts. the collection reported on my credit report does not match the amount they are seeking.
------
rash curtis and associates is attempting to collect a debt from me that i have no awareness, via threatening to damage my credit.
------
…”
The list goes of people complaining about debt collectors. Now that we have unearthed an important topic for consumers, we can easily devise an intent to handle debt collection complaints.
Bot: How may I help you?
Human: I want to report a debt collecting agency
Bot: I am sorry to hear about this, what is the name of the collection agency?
etc…
[1] https://catalog.data.gov/dataset/consumer-complaint-database
[2] https://spacy.io/usage/linguistic-features#section-pos-tagging
Manuel Amunategui - Follow me on Twitter: @amunategui